VS Code 中 Data Wrangler 快速入門指南
Data Wrangler 是一個以程式碼為中心的 VS Code 和 VS Code Jupyter Notebook 整合的資料檢視和清理工具。它提供了一個豐富的使用者介面來檢視和分析您的資料,展示有見地的列統計資訊和視覺化,並在您清理和轉換資料時自動生成 Pandas 程式碼。
以下是從 Notebook 中開啟 Data Wrangler 來分析和清理資料的示例,然後將自動生成的程式碼匯出回 Notebook。

本頁的目的是幫助您快速上手並開始使用 Data Wrangler。
設定您的環境
- 如果您還沒有安裝 Python,請先安裝 (注意: Data Wrangler 僅支援 Python 3.8 或更高版本)。
- 安裝 Data Wrangler 擴充套件
當您第一次啟動 Data Wrangler 時,它會詢問您要連線到哪個 Python 核心。它還會檢查您的機器和環境,以檢視是否安裝了所需的 Python 包,例如 Pandas。
開啟 Data Wrangler
無論何時您在 Data Wrangler 中,都處於一個沙盒環境中,這意味著您可以安全地探索和轉換資料。在您明確匯出更改之前,原始資料集不會被修改。
從 Jupyter Notebook 啟動 Data Wrangler
如果您在 Notebook 中有一個 Pandas DataFrame,在執行 df.head()、df.tail()、display(df)、print(df) 和 df 中的任何一個後,您將在單元格底部看到一個開啟 'df' 到 Data Wrangler 按鈕 (其中 df 是您的 DataFrame 的變數名)。
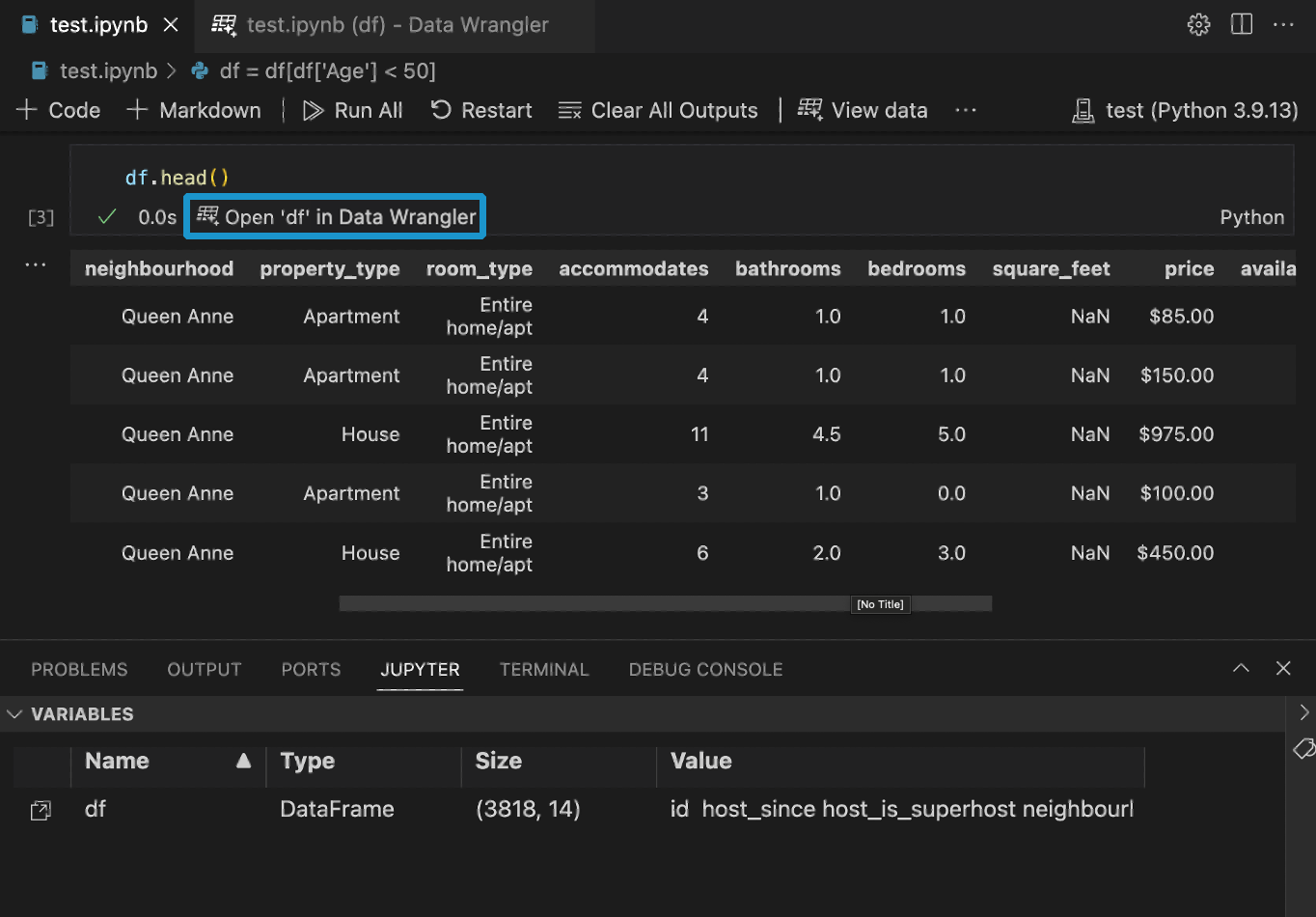
直接從檔案啟動 Data Wrangler
您也可以直接從本地檔案 (如 .csv) 啟動 Data Wrangler。要做到這一點,在 VS Code 中開啟包含您想要開啟的檔案所在的任何資料夾。在檔案資源管理器檢視中,右鍵單擊該檔案,然後單擊在 Data Wrangler 中開啟。
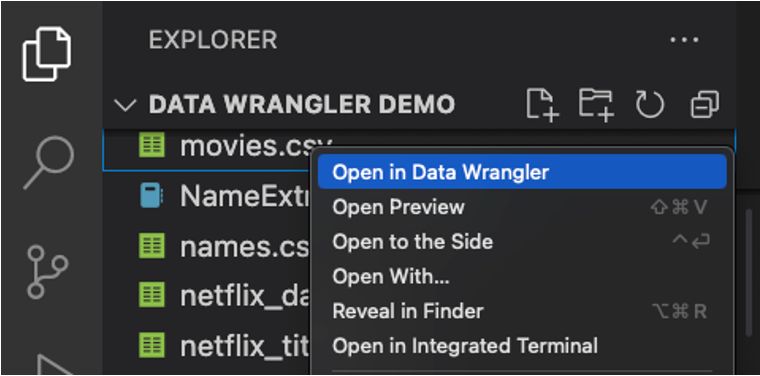
UI 導覽
Data Wrangler 在處理您的資料時有兩種模式。每種模式的詳細資訊將在下面的後續部分中進行解釋。
- 檢視模式: 檢視模式優化了介面,以便您快速檢視、過濾和排序資料。此模式非常適合對資料集進行初步探索。
- 編輯模式: 編輯模式優化了介面,以便您對資料集應用轉換、清理或修改。當您在介面中應用這些轉換時,Data Wrangler 會自動生成相關的 Pandas 程式碼,這些程式碼可以匯出回您的 Notebook 以便重複使用。
注意:預設情況下,Data Wrangler 以檢視模式開啟。您可以在設定編輯器中更改此行為 。
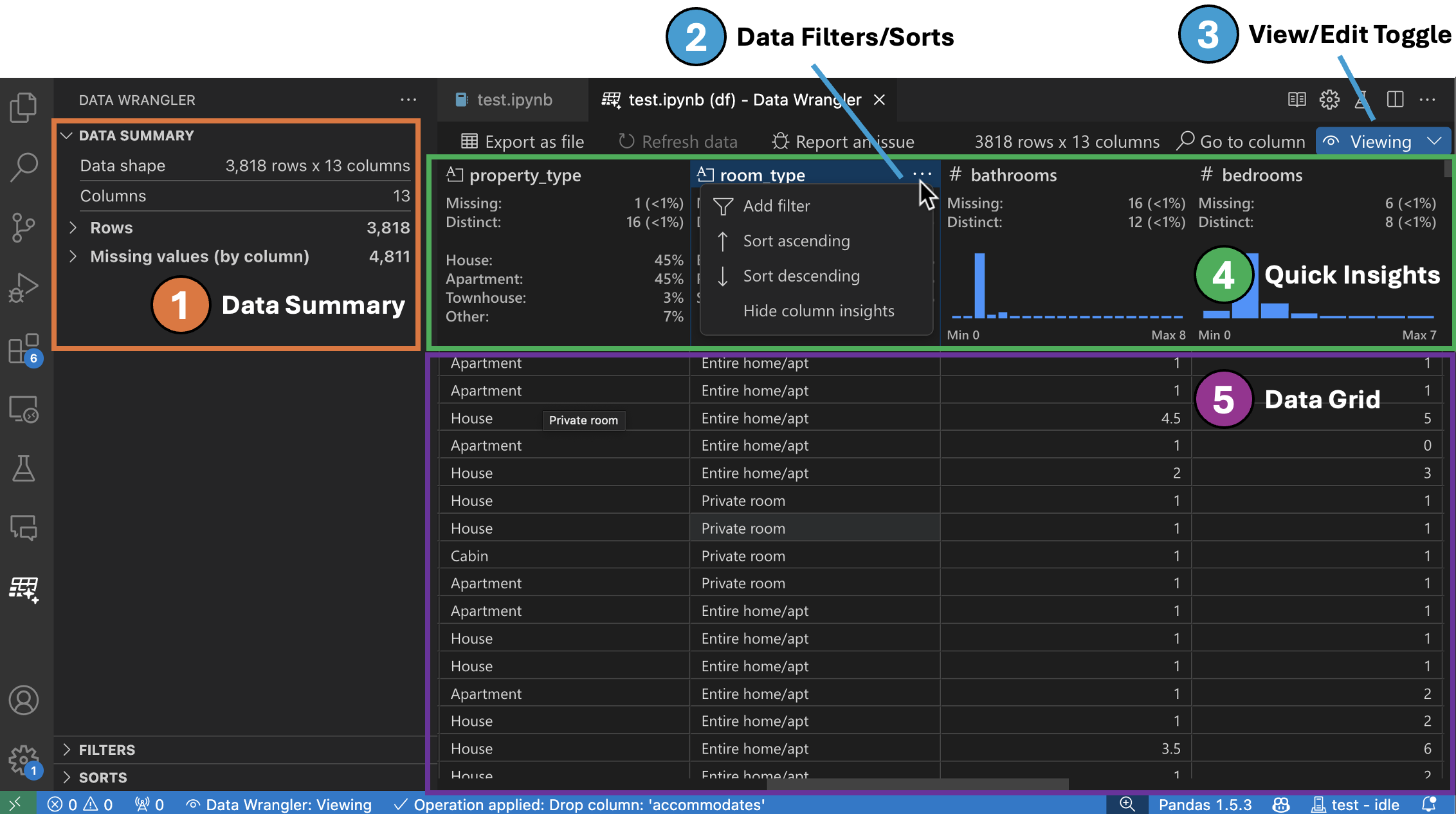
檢視模式介面
-
資料摘要面板顯示您整個資料集或特定列 (如果已選擇) 的詳細摘要統計資訊。
-
您可以從列的表頭選單中對列應用任何資料過濾器/排序。
-
在 Data Wrangler 的檢視或編輯模式之間切換,以訪問內建的資料操作。
-
快速洞察標題是您可以在其中快速檢視每列有價值資訊的地方。根據列的資料型別,快速洞察會顯示資料的分佈或資料點的頻率,以及缺失值和唯一值。
-
資料網格為您提供了一個可滾動的窗格,您可以在其中檢視整個資料集。
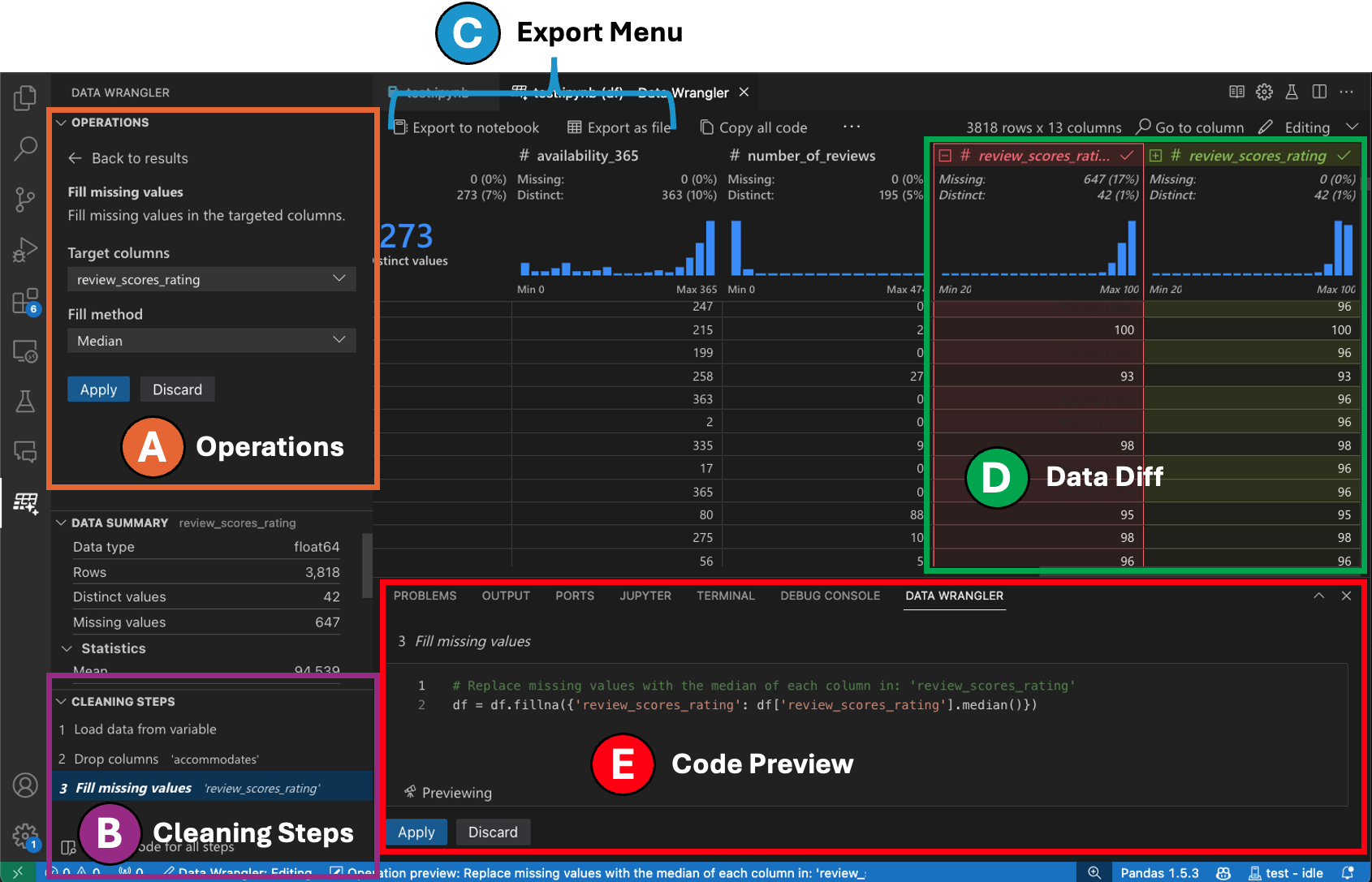
編輯模式介面
切換到編輯模式可以在 Data Wrangler 中啟用其他功能和使用者介面元素。在以下截圖中,我們使用 Data Wrangler 將最後一列中的缺失值替換為該列的中位數。
-
操作面板是您可以搜尋 Data Wrangler 所有內建資料操作的地方。操作按類別組織。
-
清理步驟面板顯示了先前應用的所有操作的列表。它使使用者能夠撤銷特定的操作或編輯最新的操作。選擇一個步驟將突出顯示資料網格中的更改,並顯示與該操作相關的生成程式碼。
-
匯出選單允許您將程式碼匯出回 Jupyter Notebook 或將資料匯出到新檔案。
-
當您選擇了一個操作並預覽其對資料的影響時,資料網格會疊加顯示您對資料所做更改的資料差異檢視。
-
程式碼預覽部分顯示當選擇一個操作時 Data Wrangler 生成的 Python 和 Pandas 程式碼。當沒有選擇操作時,它保持為空。您可以編輯生成的程式碼,這將導致資料網格突出顯示對資料的影響。
示例:替換資料集中的缺失值
給定一個數據集,一個常見的資料清理任務是處理資料中存在的任何缺失值。下面的示例展示瞭如何使用 Data Wrangler 將列中的缺失值替換為該列的中位數。雖然轉換是透過介面完成的,但 Data Wrangler 也會自動生成替換缺失值所需的 Python 和 Pandas 程式碼。

- 在操作面板中,搜尋填充缺失值操作。
- 在引數中指定您想要用什麼來替換缺失值。在這種情況下,我們將用該列的中位數來替換缺失值。
- 驗證資料網格是否向您顯示了資料差異中的正確更改。
- 驗證 Data Wrangler 生成的程式碼是否符合您的預期。
- 應用該操作,它將被新增到您的清理步驟歷史記錄中。
後續步驟
本頁介紹瞭如何快速開始使用 Data Wrangler。有關 Data Wrangler 的完整文件和教程,包括 Data Wrangler 目前支援的所有內建操作,請參閱以下頁面。