使用 VS Code 中的 AI Toolkit 轉換模型
模型轉換是一個整合的開發環境,旨在幫助開發人員和 AI 工程師在您的本地 Windows 平臺上轉換、量化、最佳化和評估預構建的機器學習模型。它為從 Hugging Face 等源轉換而來的模型提供了一個簡化的端到端體驗,最佳化它們並支援在由 NPU、GPU 和 CPU 提供支援的本地裝置上進行推理。
先決條件
- 必須安裝 VS Code。請按照以下步驟 設定 VS Code。
- 必須安裝 AI Toolkit 擴充套件。有關更多資訊,請參閱 安裝 AI Toolkit。
建立專案
在模型轉換中建立專案是轉換、最佳化、量化和評估機器學習模型的第一步。
-
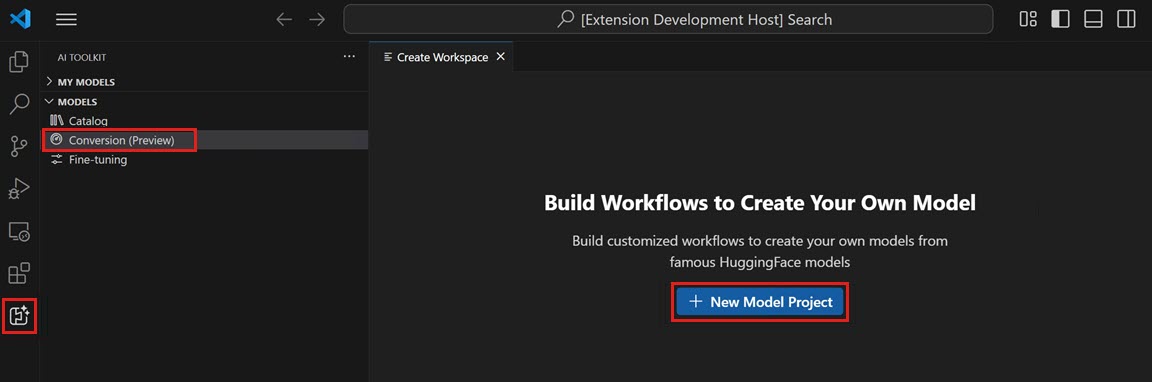
開啟 AI Toolkit 檢視,然後選擇 模型 > 轉換 以啟動模型轉換
-
透過選擇 新建模型專案 來啟動新專案
-
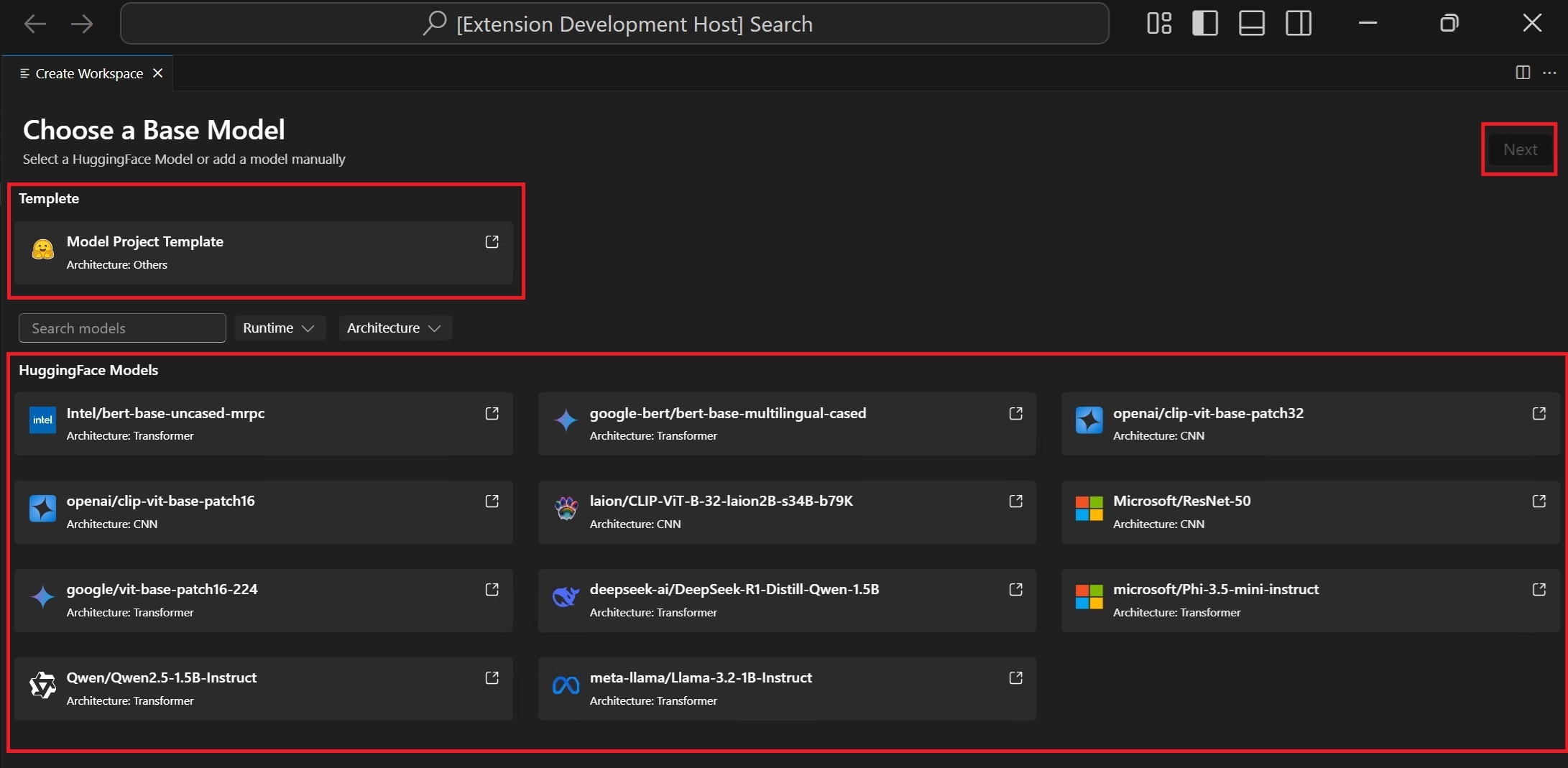
選擇基礎模型
Hugging Face 模型:從支援的模型列表中選擇帶有預定義配方的基礎模型。模型模板:如果模型不包含在基礎模型中,請選擇一個空模板用於自定義配方(高階場景)。
-
輸入專案詳細資訊:一個唯一的 專案資料夾 和一個 專案名稱。
將在您選擇的用於儲存專案檔案的位置建立具有指定專案名稱的新資料夾。
首次建立模型專案時,設定環境可能需要一些時間。您可以不完成設定。準備好後,您可以選擇重新設定環境。
每個專案都包含一個 README.md 檔案。如果關閉它,您可以透過工作區重新開啟它。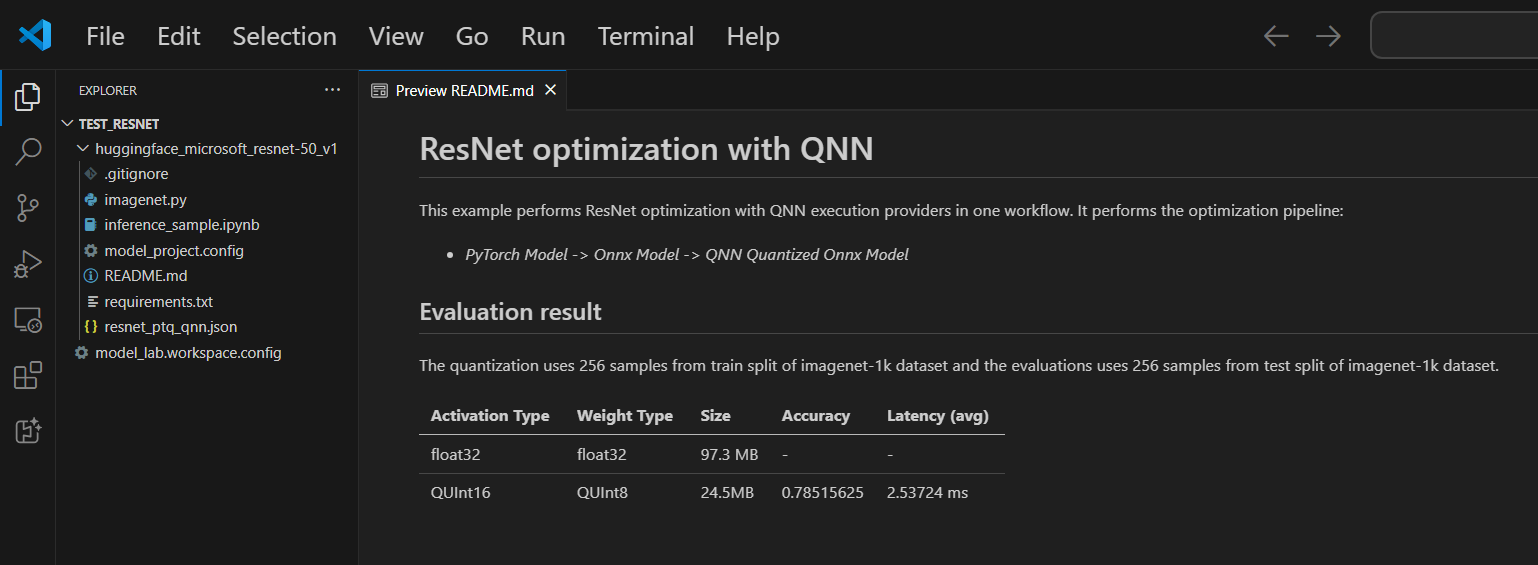
支援的模型
模型轉換目前支援不斷增長的模型列表,包括 PyTorch 格式的頂級 Hugging Face 模型。有關詳細模型列表,請參閱:模型列表
(可選)將模型新增到現有專案
-
開啟模型專案
-
選擇 模型 > 轉換,然後在右側面板中選擇 新增模型。
-
選擇一個基礎模型或模板,然後選擇 新增。
將在當前專案資料夾中建立一個包含新模型檔案的資料夾。
(可選)建立新的模型專案
-
開啟模型專案
-
選擇 模型 > 轉換,然後在右側面板中選擇 新建專案。
-
或者,關閉當前模型專案並從頭開始 建立新專案。
(可選)刪除模型專案
-
開啟模型專案並選擇 模型 > 轉換。
-
在右上角檢視中,選擇省略號(...),然後選擇 刪除 以刪除當前選定的模型專案。
執行工作流
在模型轉換中執行工作流是核心步驟,它將預構建的 ML 模型轉換為最佳化和量化的 ONNX 模型。
-
在 VS Code 中選擇 檔案 > 開啟資料夾 以開啟模型專案資料夾。
-
檢視工作流配置
- 選擇 模型 > 轉換
- 選擇工作流模板以檢視轉換配方。

轉換
工作流將始終執行轉換步驟,將模型轉換為 ONNX 格式。此步驟無法停用。
量化
本節允許您配置量化引數。
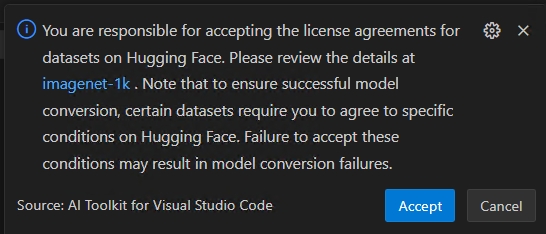
重要Hugging Face 合規性警報:在量化過程中,我們需要校準資料集。您可能會收到接受許可條款的提示,然後才能繼續。如果您錯過了通知,執行過程將暫停,等待您的輸入。請確保已啟用通知並接受了必要的許可。
-
啟用型別:這是用於表示神經網路中每個層中間輸出(啟用)的資料型別。
-
權重型別:這是用於表示模型學習引數(權重)的資料型別。
-
量化資料集:用於量化的校準資料集。
如果您的工作流使用需要 Hugging Face 上的許可協議批准的資料集(例如,ImageNet-1k),系統將提示您在繼續之前在資料集頁面上接受條款。這對於法律合規是必需的。
-
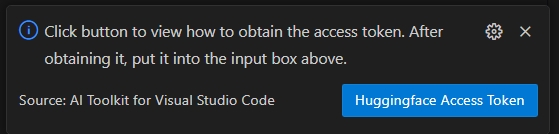
選擇 HuggingFace 訪問令牌 按鈕以獲取您的 Hugging Face 訪問令牌。
-
選擇 開啟 以開啟 Hugging Face 網站。
-
在 Hugging Face 入口網站上獲取您的令牌,然後將其貼上到快速選擇中。按 Enter。

-
-
量化資料集拆分:資料集可以有不同的拆分,如驗證、訓練和測試。
-
量化資料集大小:用於量化模型的數。
有關啟用和權重型別的更多資訊,請參閱 資料型別選擇。
您也可以停用此部分。在這種情況下,工作流將僅將模型轉換為 ONNX 格式,但不會量化模型。
評估
在本節中,您需要選擇要用於評估的執行提供程式 (EP),無論模型是在哪個平臺上轉換的。
- 在...上評估:您要評估模型的目標裝置。可能的值是
- Qualcomm NPU:要使用此功能,您需要一臺相容的 Qualcomm 裝置。
- AMD NPU:要使用此功能,您需要一臺帶有支援的 AMD NPU 的裝置。
- Intel CPU/GPU/NPU:要使用此功能,您需要一臺帶有支援的 Intel CPU/GPU/NPU 的裝置。
- NVIDIA TRT for RTX:要使用此功能,您需要一臺帶有支援 TensorRT for RTX 的 Nvidia GPU 的裝置。
- DirectML:要使用此功能,您需要一臺支援 DirectML 的 GPU 的裝置。
- CPU:任何 CPU 都可以工作。
- 評估資料集:用於評估的資料集。
- 評估資料集拆分:資料集可以有不同的拆分,如驗證、訓練和測試。
- 評估資料集大小:用於評估模型的數。
您也可以停用此部分。在這種情況下,工作流將僅將模型轉換為 ONNX 格式,但不會評估模型。
-
透過選擇 執行 來執行工作流
將使用工作流名稱和時間戳生成預設作業名稱(例如,
bert_qdq_2025-05-06_20-45-00),以便於跟蹤。在作業執行期間,您可以選擇“歷史記錄”面板中“操作”下的狀態指示器或三點選單,然後選擇 停止執行 來 取消 作業。
Hugging Face 合規性警報:在量化過程中,我們需要校準資料集。您可能會收到接受許可條款的提示,然後才能繼續。如果您錯過了通知,執行過程將暫停,等待您的輸入。請確保啟用通知並接受了必要的許可。
-
(可選)在雲中執行模型轉換
當您的本地計算機沒有足夠的計算或儲存容量時,雲轉換使您能夠在雲中執行模型轉換和量化。您需要 Azure 訂閱才能使用雲轉換。
-
從右上角的下拉選單中選擇 使用雲執行。請注意,評估 部分被停用,因為雲環境沒有目標處理器用於推理。
-
AI Toolkit 首先檢查是否已準備好用於雲轉換的 Azure 資源。如果需要,將提示您提供 Azure 訂閱和資源組以配置 Azure 資源。

-
配置完成後,配置將儲存在工作區根資料夾的
model_lab.workspace.provision.config中。此資訊將被快取,以便重複使用 Azure 資源並加快雲轉換過程。如果要使用新資源,請刪除此檔案並再次運行雲轉換。 -
將觸發 Azure 容器應用程式 (ACA) 作業來運行雲轉換。對於正在執行的作業,您可以:
- 選擇狀態連結導航到 Azure ACA 作業執行歷史頁面。
- 選擇 日誌 導航到 Azure Log Analytics。
- 選擇重新整理按鈕以獲取當前作業狀態。

-
如果您沒有可用的 GPU 用於 LLM 模型轉換,您可以使用 使用雲執行。使用雲執行選項僅支援模型轉換和量化。您需要將轉換後的模型下載到本地計算機進行評估。
使用雲執行不支援使用 DirectML 或 NVIDIA TRT for RTX 工作流進行模型轉換。
推薦列將顯示推薦的工作流,具體取決於您的裝置是否已準備好執行轉換後的模型。您仍然可以選擇偏好的工作流。模型轉換和量化:您可以在任何裝置上執行工作流,除了 LLM 模型。量化配置針對 NPU 進行了最佳化。如果目標系統不是 NPU,建議取消選中此步驟。
LLM 模型量化:如果您想量化 LLM 模型,則需要 Nvidia GPU。
如果您想在另一臺具有 GPU 的裝置上量化模型,您可以自行設定環境,請參閱 ManualConversionOnGPU。請注意,只有“量化”步驟需要 GPU。量化後,您可以在 NPU 或 CPU 上評估模型。
重新評估的提示
模型成功轉換後,您可以使用重新評估功能再次執行評估,而無需進行模型轉換。
轉到“歷史記錄”面板,找到模型執行作業。選擇“操作”下的三點選單,然後選擇 重新評估 模型。
您可以為重新評估選擇不同的 EP 或資料集

失敗作業的提示
如果您的作業被取消或失敗,您可以選擇作業名稱來調整工作流並重新執行作業。為避免意外覆蓋,每次執行都會建立一個新的歷史記錄資料夾,其中包含其自己的配置和結果。
某些工作流可能要求您首先登入 Hugging Face。如果您的作業因輸出類似 huggingface_hub.errors.LocalTokenNotFoundError: Token is required ('token=True'), but no token found. You need to provide a token or be logged in to Hugging Face with 'hf auth login' or 'huggingface_hub.login' 而失敗,請導航到 https://huggingface.tw/settings/tokens 並按照說明完成登入過程,然後重試。
如果您的重新評估因輸出警告 Microsoft Visual C++ Redistributable is not installed 而失敗,您需要手動安裝以下軟體包
- Microsoft Visual C++ Redistributable
- (ARM64 可選)從 Microsoft C++ Build Tools 下載。安裝時還請勾選
使用 C++ 進行桌面開發工作負載。
檢視結果
“轉換”中的“歷史記錄”面板是您跟蹤、檢視和管理所有工作流執行的中央儀表板。每次執行模型轉換和評估時,“歷史記錄”面板中都會建立一個新條目——確保完全的可追溯性和可重複性。
-
找到您想要檢視的工作流執行。每次執行都會列出狀態指示器(例如,成功、已取消)。
-
選擇執行名稱以檢視轉換配置
-
選擇狀態指示器下的 日誌 以檢視日誌和詳細的執行結果
-
模型成功轉換後,您可以在“指標”下檢視評估結果。指標(如準確性、延遲和吞吐量)會與每次執行一起顯示。

-
您可以選擇“操作”下的三點選單,與轉換後的模型進行互動。

複製轉換後的模型路徑
- 從下拉選單中選擇 複製模型路徑。輸出的轉換後的模型路徑(例如
c:/{workspace}/{model_project}/history/{workflow}/model/model.onnx)將複製到剪貼簿以供參考。對於 LLM 模型,將複製輸出資料夾。
使用示例筆記本進行模型推理
- 從下拉選單中選擇 示例中推理。
- 選擇 Python 環境
- 系統將提示您選擇一個 Python 虛擬環境。預設執行時是:
C:\Users\{user_name}\.aitk\bin\model_lab_runtime\Python-WCR-win32-x64-3.12.9。 - 請注意,預設執行時包含所有必需項,否則,請手動安裝 requirements.txt。
- 系統將提示您選擇一個 Python 虛擬環境。預設執行時是:
- 示例將在 Jupyter Notebook 中啟動。您可以自定義輸入資料或引數來測試不同的場景。
對於使用雲轉換的模型,狀態變為 成功 後,選擇雲下載圖示將輸出模型下載到本地計算機。
為避免覆蓋任何現有的本地檔案(如配置或與歷史記錄相關的檔案),僅下載缺失的檔案。如果您想下載乾淨的副本,請先刪除本地資料夾,然後重新下載。
模型相容性:確保轉換後的模型支援推理示例中指定的 EP。
示例位置:推理示例與歷史資料夾中的執行工件一起儲存。
匯出並與他人分享
轉到“歷史記錄”面板。選擇 匯出 以與他人共享模型專案。這將複製不包含歷史記錄資料夾的模型專案。如果您想與他人共享模型,請選擇相應的作業。這將複製包含模型及其配置的選定歷史記錄資料夾。
您學到了什麼
在本文中,您學習瞭如何
- 在 VS Code 的 AI Toolkit 中建立模型轉換專案。
- 配置轉換工作流,包括量化和評估設定。
- 執行轉換工作流,將預構建模型轉換為最佳化的 ONNX 模型。
- 檢視轉換結果,包括指標和日誌。
- 使用示例筆記本進行模型推理和測試。
- 匯出並與他人共享模型專案。
- 使用不同的執行提供程式或資料集重新評估模型。
- 處理失敗的作業並調整配置以重新執行。
- 瞭解支援的模型及其轉換和量化要求。