VS Code 中的資料科學教程
本教程演示瞭如何使用 Visual Studio Code 和 Microsoft Python 擴充套件以及常見的資料科學庫來探索基本的資料科學場景。具體來說,您將使用泰坦尼克號的乘客資料,學習如何設定資料科學環境、匯入和清理資料、建立用於預測泰坦尼克號上生存情況的機器學習模型,以及評估生成模型的準確性。
先決條件
完成本教程需要進行以下安裝。如果尚未安裝,請確保進行安裝。
-
從 Visual Studio Marketplace 安裝 VS Code 的 Python 擴充套件 和 VS Code 的 Jupyter 擴充套件。有關安裝擴充套件的更多詳細資訊,請參閱 擴充套件市場。這兩個擴充套件都由 Microsoft 釋出。
-
注意:如果您已安裝完整的 Anaconda 發行版,則無需安裝 Miniconda。或者,如果您不想使用 Anaconda 或 Miniconda,可以建立一個 Python 虛擬環境,並使用 pip 安裝本教程所需的包。如果您選擇此路徑,則需要安裝以下包:pandas、jupyter、seaborn、scikit-learn、keras 和 tensorflow。
設定資料科學環境
Visual Studio Code 和 Python 擴充套件為資料科學場景提供了出色的編輯器。藉助對 Jupyter 筆記本的本機支援以及 Anaconda,可以輕鬆入門。在本節中,您將為本教程建立一個工作區,建立一個包含本教程所需資料科學模組的 Anaconda 環境,並建立一個 Jupyter 筆記本,您將使用它來建立機器學習模型。
-
首先,為資料科學教程建立一個 Anaconda 環境。開啟 Anaconda 命令提示符,然後執行
conda create -n myenv python=3.10 pandas jupyter seaborn scikit-learn keras tensorflow來建立一個名為 myenv 的環境。有關建立和管理 Anaconda 環境的更多資訊,請參閱 Anaconda 文件。 -
接下來,在方便的位置建立一個資料夾,作為本教程的 VS Code 工作區,將其命名為
hello_ds。 -
透過執行 VS Code 並使用 檔案 > 開啟資料夾 命令,在 VS Code 中開啟專案資料夾。由於您建立了該資料夾,因此可以安全地信任開啟資料夾。
-
VS Code 啟動後,建立將用於本教程的 Jupyter 筆記本。開啟命令面板(⇧⌘P (Windows、Linux Ctrl+Shift+P)),然後選擇 建立:新的 Jupyter 筆記本。

注意:或者,您也可以從 VS Code 檔案資源管理器中使用新建檔案圖示建立一個名為
hello.ipynb的筆記本檔案。 -
使用 檔案 > 另存為... 將檔案另存為
hello.ipynb。 -
檔案建立後,您應該會在筆記本編輯器中看到已開啟的 Jupyter 筆記本。有關本機 Jupyter 筆記本支援的更多資訊,您可以閱讀 Jupyter Notebooks 主題。
-
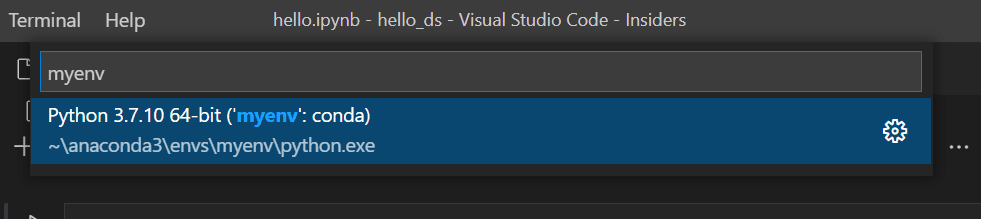
現在,在筆記本的右上角選擇 選擇核心。

-
選擇上面建立的 Python 環境來執行您的核心。
-
要從 VS Code 的整合終端管理您的環境,請使用 (⌃` (Windows、Linux Ctrl+`)) 開啟它。如果您的環境未啟用,您可以在終端中像平常一樣啟用它(
conda activate myenv)。
準備資料
本教程使用 泰坦尼克號資料集,該資料集可在 OpenML.org 上獲取,該資料集來自範德堡大學生物統計學系,位於 https://hbiostat.org/data。泰坦尼克號資料提供了關於泰坦尼克號乘客生存情況以及乘客特徵(如年齡和船票等級)的資訊。利用這些資料,本教程將建立一個模型來預測給定乘客是否會在泰坦尼克號沉沒中倖存下來。本節演示瞭如何在 Jupyter 筆記本中載入和操作資料。
-
首先,從 hbiostat.org 下載泰坦尼克號資料,儲存為 CSV 檔案(右上角有下載連結),命名為
titanic3.csv,並將其儲存到上節中建立的hello_ds資料夾。 -
如果您尚未在 VS Code 中開啟該檔案,請轉到 檔案 > 開啟資料夾,然後開啟
hello_ds資料夾和 Jupyter 筆記本(hello.ipynb)。 -
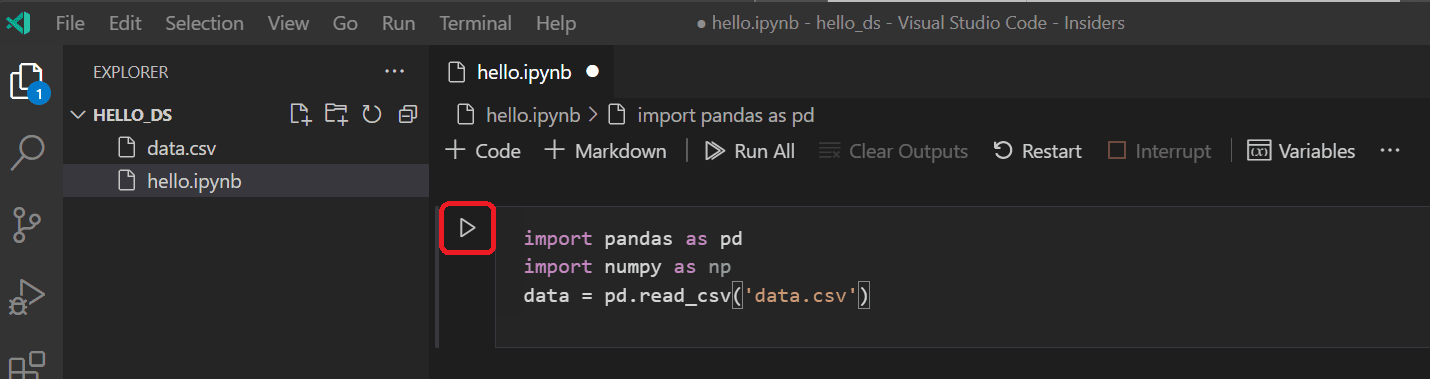
在 Jupyter 筆記本中,首先匯入 pandas 和 numpy 庫,這兩個庫是用於操作資料的常用庫,並將泰坦尼克號資料載入到 pandas DataFrame 中。為此,請將下面的程式碼複製到筆記本的第一個單元格中。有關在 VS Code 中使用 Jupyter 筆記本的更多指導,請參閱 使用 Jupyter Notebooks 文件。
import pandas as pd import numpy as np data = pd.read_csv('titanic3.csv') -
現在,使用“執行單元格”圖示或 Shift+Enter 快捷鍵執行該單元格。
-
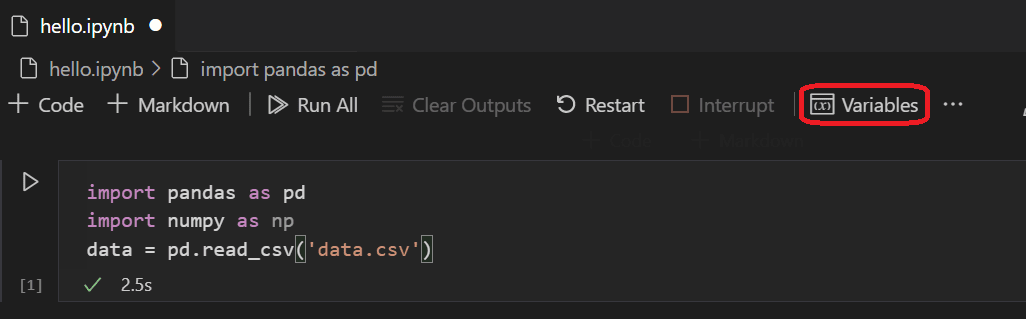
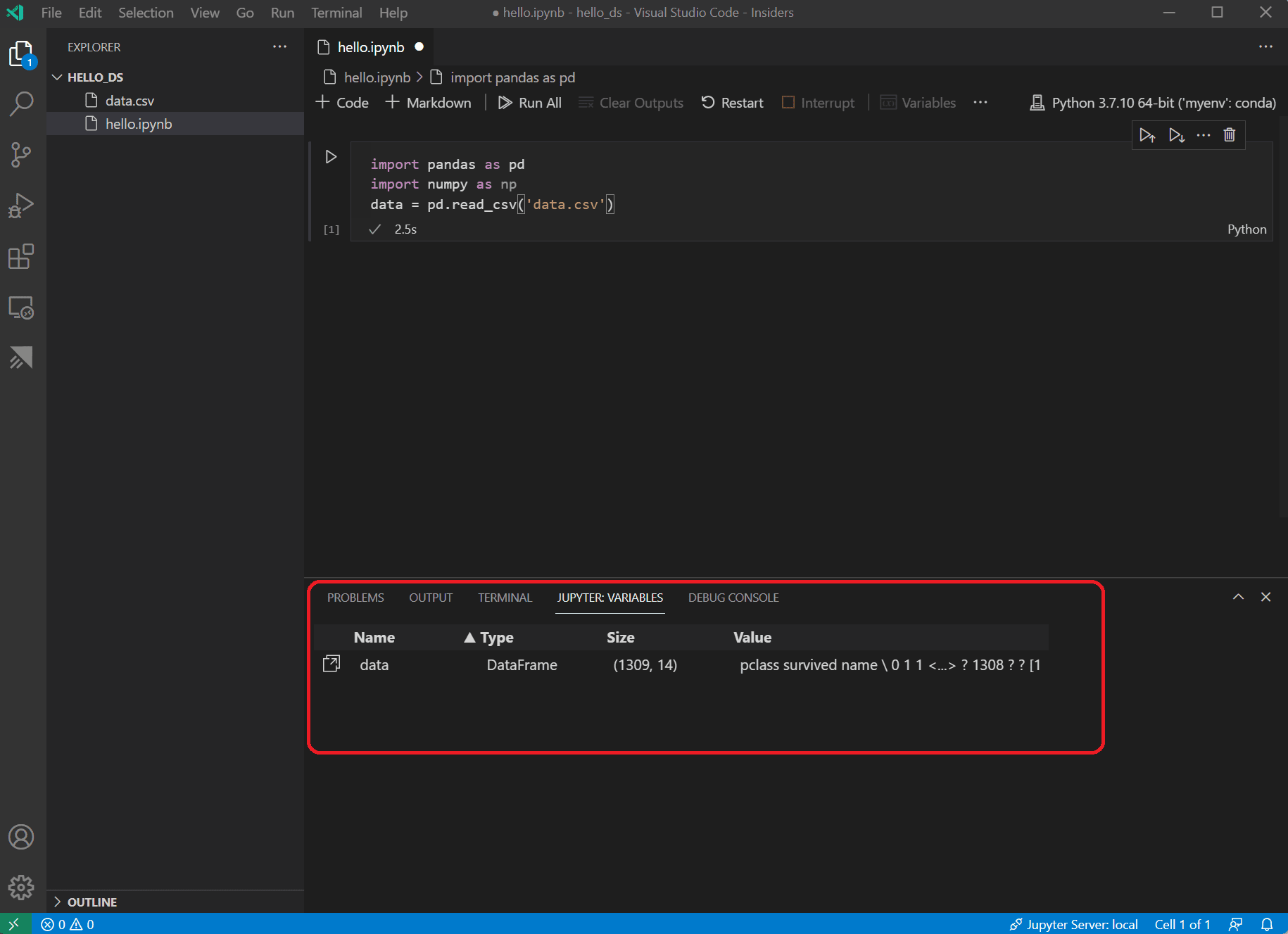
單元格執行完成後,您可以透過“變數資源管理器”和“資料檢視器”檢視已載入的資料。首先選擇筆記本頂部工具欄中的 變數 圖示。
-
VS Code 底部將開啟一個 JUPYTER: VARIABLES 窗格。其中包含您當前執行的核心中已定義變數的列表。
-
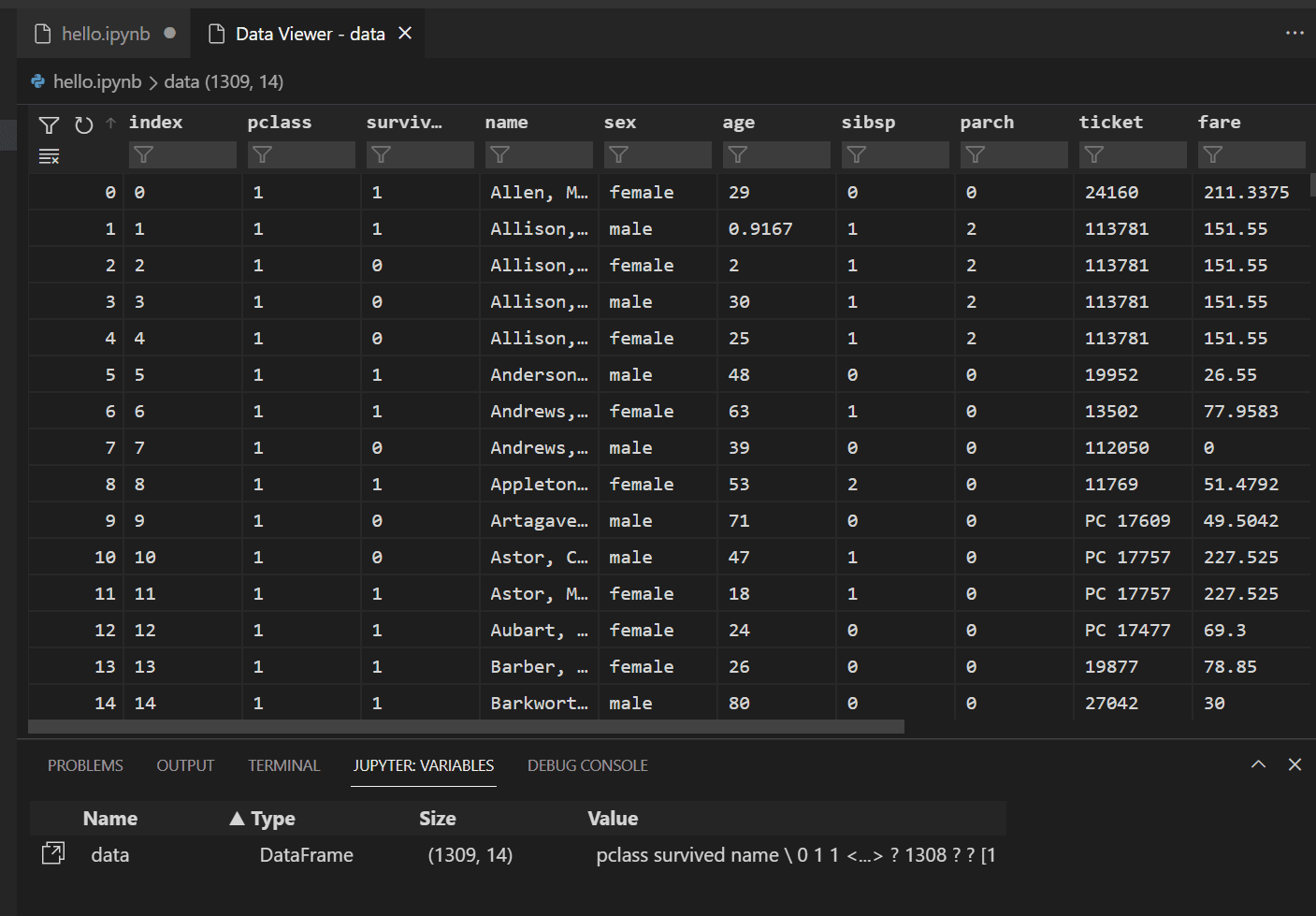
要檢視之前載入的 Pandas DataFrame 中的資料,請選擇
data變數左側的資料檢視器圖示。
-
使用資料檢視器檢視、排序和篩選資料行。在檢視資料後,對其中某些方面進行繪圖可能有助於視覺化不同變數之間的關係。
或者,您可以使用其他擴充套件提供的資料檢視體驗,例如 Data Wrangler。Data Wrangler 擴充套件提供了一個豐富的使用者介面,可以顯示有關您資料見解的資訊,並幫助您執行資料分析、質量檢查、轉換等操作。在我們的文件中瞭解有關 Data Wrangler 擴充套件 的更多資訊。
-
在可以繪圖之前,需要確保資料沒有問題。如果您檢視泰坦尼克號 CSV 檔案,您會注意到一個問號 ("?") 被用來標識資料不可用的單元格。
雖然 Pandas 可以將此值讀入 DataFrame,但像 age 這樣的列將設定為 object 資料型別而不是數字資料型別,這對於繪圖來說是個問題。
可以透過將問號替換為 Pandas 可以理解的缺失值來糾正此問題。將以下程式碼新增到筆記本的下一個單元格中,以用 numpy NaN 值替換 age 和 fare 列中的問號。請注意,替換值後還需要更新列的資料型別。
提示:要新增新單元格,可以使用現有單元格左下角顯示的插入單元格圖示。或者,您也可以使用 Esc 進入命令模式,然後按 B 鍵。
data.replace('?', np.nan, inplace= True) data = data.astype({"age": np.float64, "fare": np.float64})注意:如果您需要檢視用於某個列的資料型別,可以使用 DataFrame dtypes 屬性。
-
現在資料已準備就緒,您可以使用 seaborn 和 matplotlib 檢視資料集中某些列與生存率的關係。將以下程式碼新增到筆記本的下一個單元格並執行它,以檢視生成的圖表。
import seaborn as sns import matplotlib.pyplot as plt fig, axs = plt.subplots(ncols=5, figsize=(30,5)) sns.violinplot(x="survived", y="age", hue="sex", data=data, ax=axs[0]) sns.pointplot(x="sibsp", y="survived", hue="sex", data=data, ax=axs[1]) sns.pointplot(x="parch", y="survived", hue="sex", data=data, ax=axs[2]) sns.pointplot(x="pclass", y="survived", hue="sex", data=data, ax=axs[3]) sns.violinplot(x="survived", y="fare", hue="sex", data=data, ax=axs[4])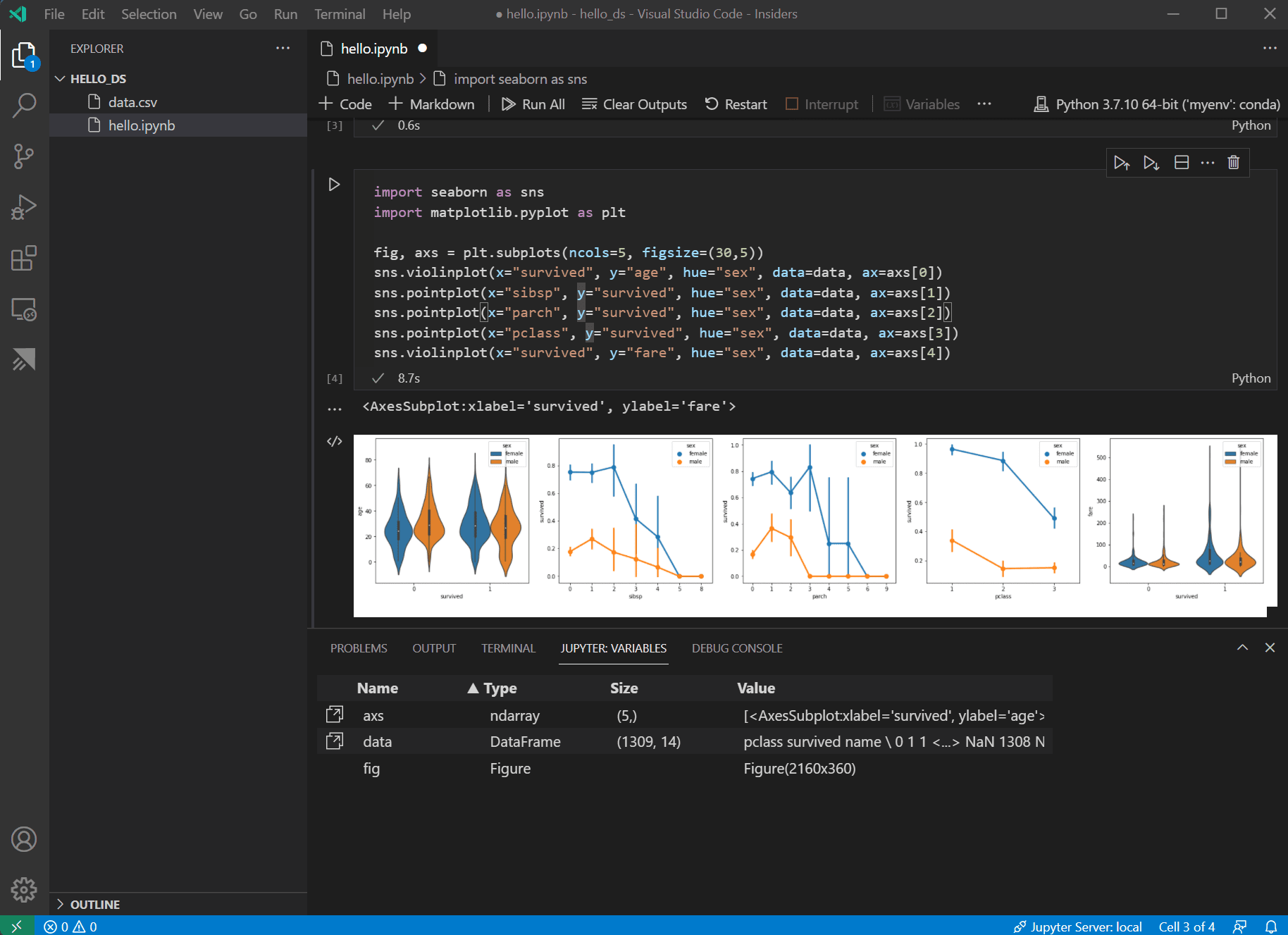
提示:要快速複製圖表,可以將滑鼠懸停在圖表右上角,然後點擊出現的 複製到剪貼簿 按鈕。您還可以透過點選 展開影像 按鈕來更好地檢視圖表的詳細資訊。

-
這些圖表有助於瞭解生存率與資料輸入變數之間的一些關係,但也可以使用 pandas 來計算相關性。為此,所有使用的變數都需要是數值型的,才能進行相關性計算,而當前性別儲存為字串。要將這些字串值轉換為整數,請新增並執行以下程式碼。
data.replace({'male': 1, 'female': 0}, inplace=True) -
現在,您可以分析所有輸入變數之間的相關性,以確定哪些特徵最適合作為機器學習模型的輸入。值越接近 1,值與結果之間的相關性就越高。使用以下程式碼將所有變數與生存率之間的關係進行相關性分析。
data.corr(numeric_only=True).abs()[["survived"]]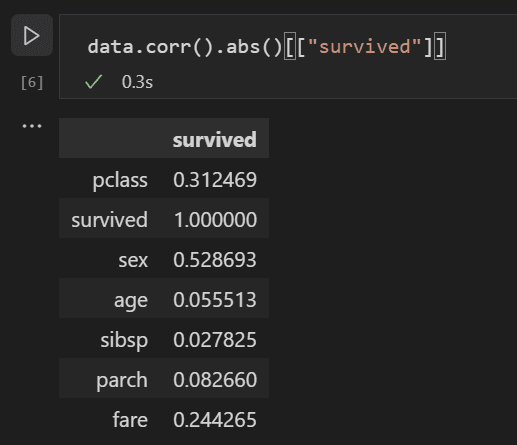
-
檢視相關性結果,您會注意到像性別這樣的某些變數與生存率具有相當高的相關性,而像親屬(sibsp = 兄弟姐妹或配偶,parch = 父母或子女)之類的其他變數似乎相關性很小。
讓我們假設 sibsp 和 parch 在影響生存率方面是相關的,並將它們分組到一個名為“relatives”的新列中,以檢視它們的組合是否與生存率具有更高的相關性。為此,您將檢查給定乘客的 sibsp 和 parch 的數量是否大於 0,如果是,則可以認為他們有親屬在船上。
使用以下程式碼在資料集中建立一個名為
relatives的新變數和列,並再次檢查相關性。data['relatives'] = data.apply (lambda row: int((row['sibsp'] + row['parch']) > 0), axis=1) data.corr(numeric_only=True).abs()[["survived"]]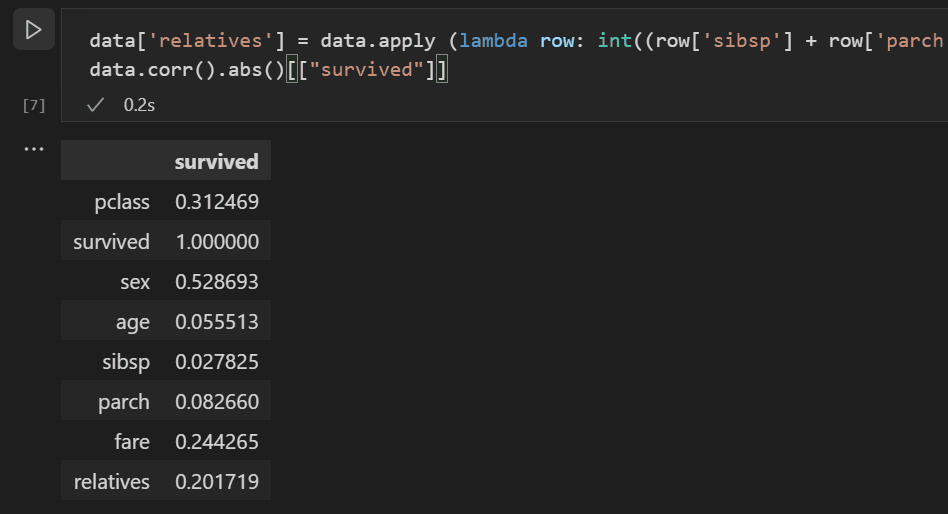
-
您會注意到,實際上,當從一個人是否有親屬的角度來看,而不是看有多少親屬時,與生存率的相關性會更高。有了這些資訊,您就可以從資料集中刪除低值的 sibsp 和 parch 列,以及任何包含 NaN 值的行,從而得到一個可用於訓練模型的資料集。
data = data[['sex', 'pclass','age','relatives','fare','survived']].dropna()注意:儘管年齡的直接相關性較低,但仍然保留它,因為結合其他輸入因素,它可能仍然具有相關性。
訓練和評估模型
資料集準備就緒後,您就可以開始建立模型了。在本節中,您將使用 scikit-learn 庫(因為它提供了一些有用的輔助函式)來預處理資料集,訓練一個分類模型來確定泰坦尼克號的生存率,然後使用該模型和測試資料來確定其準確性。
-
訓練模型的第一步通常是將資料集劃分為訓練資料和驗證資料。這允許您使用一部分資料來訓練模型,另一部分資料來測試模型。如果您將所有資料都用於訓練模型,那麼您將無法估計它在模型尚未見過的資料上的實際效能。scikit-learn 庫的一個優點是它提供了一個專門用於將資料集拆分為訓練資料和測試資料的函式。
在筆記本中新增一個包含以下程式碼的單元格並執行它,以拆分資料。
from sklearn.model_selection import train_test_split x_train, x_test, y_train, y_test = train_test_split(data[['sex','pclass','age','relatives','fare']], data.survived, test_size=0.2, random_state=0) -
接下來,您將對輸入進行標準化,以便所有特徵都被同等對待。例如,在資料集中,age 的值範圍為 0-100 左右,而 gender 僅為 1 或 0。透過標準化所有變數,可以確保值範圍都相同。在新的程式碼單元格中使用以下程式碼來縮放輸入值。
from sklearn.preprocessing import StandardScaler sc = StandardScaler() X_train = sc.fit_transform(x_train) X_test = sc.transform(x_test) -
您可以從許多不同的機器學習演算法中進行選擇來建模資料。scikit-learn 庫還支援其中 許多,以及一個 圖表 來幫助您選擇適合您場景的演算法。目前,讓我們使用 樸素貝葉斯演算法,這是一種常見的分類問題演算法。新增一個包含以下程式碼的單元格來建立和訓練演算法。
from sklearn.naive_bayes import GaussianNB model = GaussianNB() model.fit(X_train, y_train) -
有了訓練好的模型,您現在可以嘗試使用從訓練中保留的測試資料集。新增並執行以下程式碼來預測測試資料的結果並計算模型的準確性。
from sklearn import metrics predict_test = model.predict(X_test) print(metrics.accuracy_score(y_test, predict_test))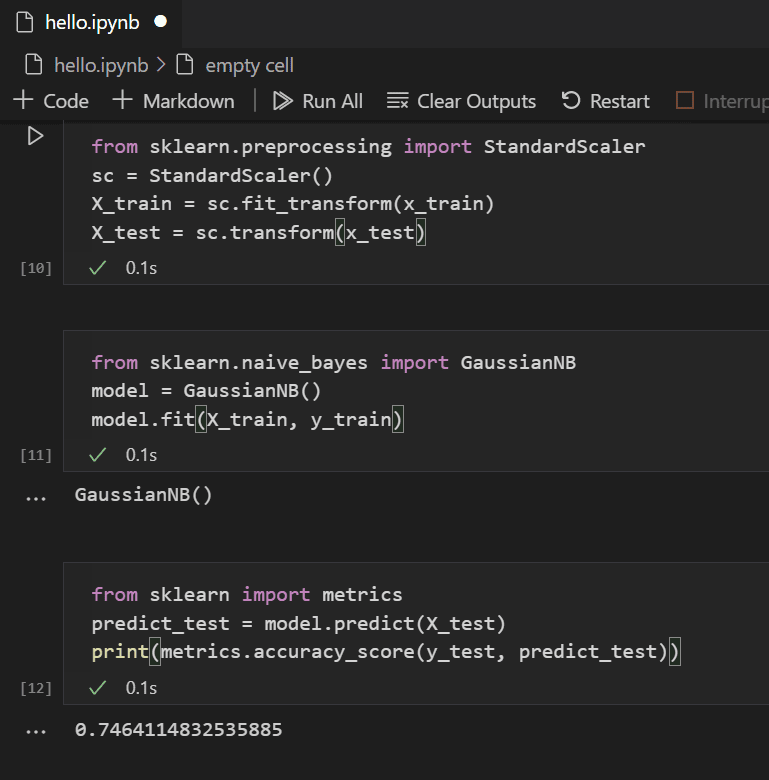
檢視測試資料的結果,您會發現訓練好的演算法在估計生存率方面有約 75% 的成功率。
(可選)使用神經網路
神經網路是一種模型,它使用權重和啟用函式,模擬人腦神經元的方面,以根據提供的輸入確定結果。與之前檢視的機器學習演算法不同,神經網路是一種深度學習形式,在這種形式下,您不需要提前知道您問題集的理想演算法。它可以用於許多不同的場景,分類是其中之一。在本節中,您將使用 Keras 庫和 TensorFlow 來構建神經網路,並探索它如何處理泰坦尼克號資料集。
-
第一步是匯入所需的庫並建立模型。在這種情況下,您將使用 Sequential 神經網路,這是一種分層神經網路,其中有多個層按順序相互饋送。
from keras.models import Sequential from keras.layers import Dense model = Sequential() -
定義模型後,下一步是新增神經網路的層。目前,讓我們保持簡單,只使用三層。新增以下程式碼來建立神經網路的層。
model.add(Dense(5, kernel_initializer = 'uniform', activation = 'relu', input_dim = 5)) model.add(Dense(5, kernel_initializer = 'uniform', activation = 'relu')) model.add(Dense(1, kernel_initializer = 'uniform', activation = 'sigmoid'))- 第一層將設定為維度為 5,因為您有五個輸入:性別、船票等級、年齡、親屬和票價。
- 最後一層必須輸出 1,因為您想要一個表示乘客是否會生存的一維輸出。
- 中間層保持為 5 是為了簡單起見,儘管該值可能不同。
整流線性單元 (relu) 啟用函式用作前兩層的良好通用啟用函式,而 sigmoid 啟用函式是最後一層所必需的,因為您想要的輸出(乘客是否生存)需要縮放到 0-1 的範圍內(乘客生存的機率)。
您也可以使用此程式碼行檢視所構建模型的摘要
model.summary()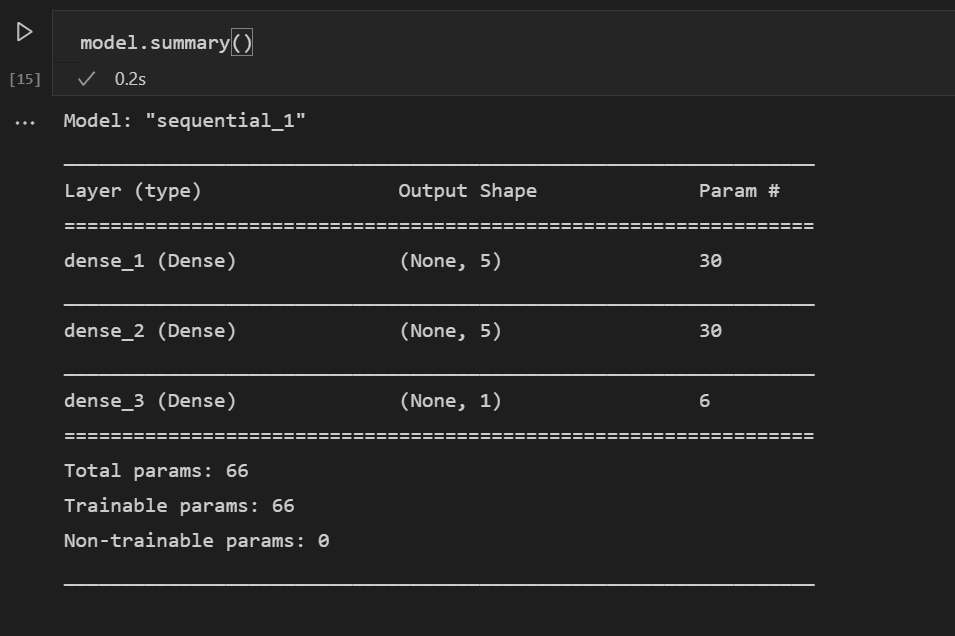
-
模型建立後,需要對其進行編譯。作為其中的一部分,您需要定義將使用的最佳化器型別、如何計算損失以及應最佳化哪些指標。新增以下程式碼來構建和訓練模型。您會注意到,訓練後,準確率為約 61%。
注意:此步驟可能需要幾秒鐘到幾分鐘的時間才能完成,具體取決於您的機器。
model.compile(optimizer="adam", loss='binary_crossentropy', metrics=['accuracy']) model.fit(X_train, y_train, batch_size=32, epochs=50)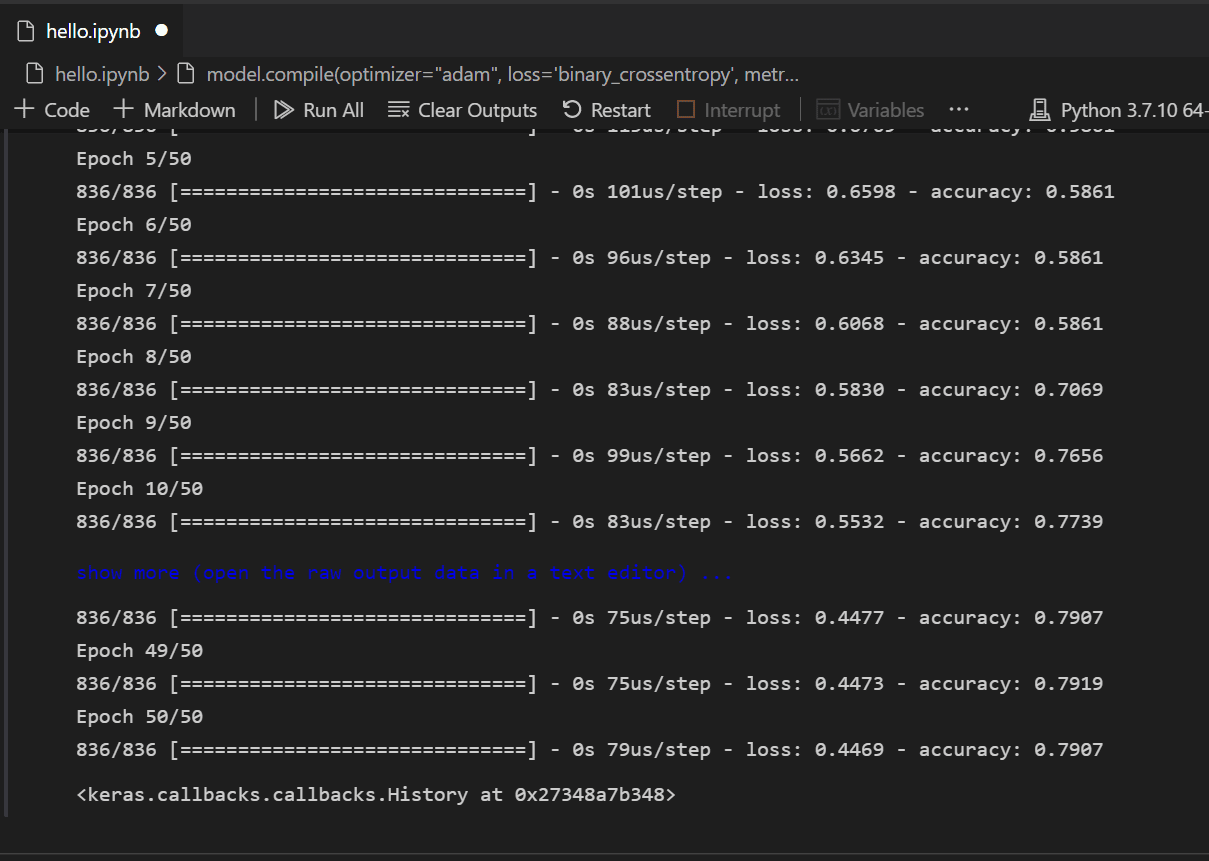
-
模型構建和訓練完成後,我們可以檢視它在測試資料上的表現。
y_pred = np.rint(model.predict(X_test).flatten()) print(metrics.accuracy_score(y_test, y_pred))
與訓練類似,您會注意到現在您在預測乘客生存率方面有 79% 的準確率。使用這個簡單的神經網路,結果比之前嘗試的樸素貝葉斯分類器的 75% 準確率要好。
後續步驟
現在您已經熟悉了在 Visual Studio Code 中執行機器學習的基礎知識,這裡有一些其他 Microsoft 資源和教程供您檢視。
- 資料科學配置檔案模板 - 使用一組精選的擴充套件、設定和程式碼片段建立新的 配置檔案。
- 瞭解更多關於在 Visual Studio Code 中使用 Jupyter Notebooks(影片)。
- 開始使用 VS Code 的 Azure 機器學習,利用 Azure 的強大功能部署和最佳化您的模型。
- 在 Azure Open Data Sets 上查詢更多可供探索的資料。