語法高亮指南
語法高亮決定了 Visual Studio Code 編輯器中原始碼顯示的顏色和樣式。它負責將 JavaScript 中的 if 或 for 等關鍵字與字串、註釋和變數名以不同的顏色區分開。
語法高亮包含兩個組成部分:
在深入細節之前,一個好的開始是使用 作用域檢查器 工具,探索原始碼檔案中存在的標記,以及它們匹配的主題規則。要檢視語義和語法標記,請在 TypeScript 檔案上使用內建主題(例如 Dark+)。
分詞
文字分詞是將文字分解成片段,併為每個片段分配一個標記型別。
VS Code 的分詞引擎由 TextMate 語法 提供支援。TextMate 語法是正則表示式的結構化集合,以 plist (XML) 或 JSON 檔案形式編寫。VS Code 擴充套件可以透過 grammars 貢獻點來提供語法。
TextMate 分詞引擎與渲染器在同一程序中執行,標記會在使用者鍵入時更新。標記不僅用於語法高亮,還用於將原始碼分類為註釋、字串、正則表示式等區域。
從 1.43 版本開始,VS Code 還允許擴充套件透過 語義標記提供程式 提供分詞。語義提供程式通常由對原始碼檔案有更深入理解並能在專案上下文中解析符號的語言伺服器實現。例如,一個常量變數名可以在整個專案中以常量高亮顯示,而不僅僅是在其宣告處。
基於語義標記的高亮被認為是 TextMate 分詞高亮的補充。語義高亮建立在語法高亮之上。由於語言伺服器載入和分析專案可能需要一些時間,語義標記高亮可能會出現短暫延遲。
本文重點介紹基於 TextMate 的分詞。語義分詞和主題化將在 語義高亮指南 中進行解釋。
TextMate 語法
VS Code 使用 TextMate 語法 作為語法分詞引擎。TextMate 語法最初為 TextMate 編輯器發明,由於開源社群建立和維護了大量的語言包,已被許多其他編輯器和 IDE 採用。
TextMate 語法依賴於 Oniguruma 正則表示式,通常以 plist 或 JSON 格式編寫。你可以在 這裡 找到 TextMate 語法的精彩介紹,並可以檢視現有的 TextMate 語法以瞭解更多它們的工作原理。
TextMate 標記和作用域
標記(Token)是一個或多個屬於同一程式元素的字元。示例標記包括 + 和 * 等運算子,myVar 等變數名,或 "my string" 等字串。
每個標記都關聯一個作用域(scope),用於定義標記的上下文。作用域是一個點分隔的識別符號列表,用於指定當前標記的上下文。例如,JavaScript 中的 + 操作的作用域是 keyword.operator.arithmetic.js。
主題透過將作用域對映到顏色和樣式來實現語法高亮。TextMate 提供了一個 常見作用域列表,許多主題都以這些作用域為目標。為了讓你的語法儘可能廣泛地獲得支援,請嘗試基於現有作用域進行構建,而不是定義新的作用域。
作用域是巢狀的,因此每個標記也與一個父作用域列表相關聯。下面的示例使用 作用域檢查器 來顯示一個簡單的 JavaScript 函式中 + 運算子的作用域層次結構。最具體的作用域列在頂部,然後是更通用的父作用域。
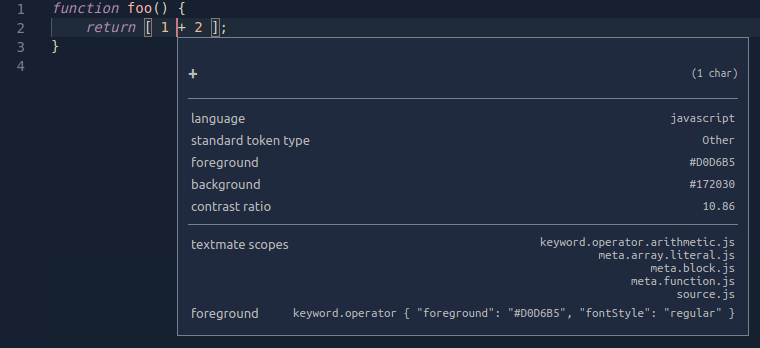
父作用域資訊也用於主題化。當主題定位某個作用域時,所有具有該父作用域的標記都將被著色,除非主題為其單個作用域提供了更具體著色。
貢獻基本語法
VS Code 支援 JSON 格式的 TextMate 語法。這些語法透過 grammars 貢獻點 進行貢獻。
每個語法貢獻都指定:語法適用的語言識別符號、語法標記的頂層作用域名稱,以及語法檔案的相對路徑。下面的示例顯示了為虛構的 abc 語言所做的語法貢獻。
{
"contributes": {
"languages": [
{
"id": "abc",
"extensions": [".abc"]
}
],
"grammars": [
{
"language": "abc",
"scopeName": "source.abc",
"path": "./syntaxes/abc.tmGrammar.json"
}
]
}
}
語法檔案本身由一個頂層規則組成。這通常分為一個 patterns 部分,列出程式的頂層元素,以及一個 repository,定義每個元素。語法中的其他規則可以透過 { "include": "#id" } 來引用 repository 中的元素。
示例 abc 語法將字母 a、b 和 c 標記為關鍵字,並將括號巢狀標記為表示式。
{
"scopeName": "source.abc",
"patterns": [{ "include": "#expression" }],
"repository": {
"expression": {
"patterns": [{ "include": "#letter" }, { "include": "#paren-expression" }]
},
"letter": {
"match": "a|b|c",
"name": "keyword.letter"
},
"paren-expression": {
"begin": "\\(",
"end": "\\)",
"beginCaptures": {
"0": { "name": "punctuation.paren.open" }
},
"endCaptures": {
"0": { "name": "punctuation.paren.close" }
},
"name": "expression.group",
"patterns": [{ "include": "#expression" }]
}
}
}
語法引擎將嘗試依次將 expression 規則應用於文件中的所有文字。對於一個簡單的程式,例如:
a
(
b
)
x
(
(
c
xyz
)
)
(
a
示例語法生成以下作用域(從左到右,從最具體到最不具體的作用域):
a keyword.letter, source.abc
( punctuation.paren.open, expression.group, source.abc
b keyword.letter, expression.group, source.abc
) punctuation.paren.close, expression.group, source.abc
x source.abc
( punctuation.paren.open, expression.group, source.abc
( punctuation.paren.open, expression.group, expression.group, source.abc
c keyword.letter, expression.group, expression.group, source.abc
xyz expression.group, expression.group, source.abc
) punctuation.paren.close, expression.group, expression.group, source.abc
) punctuation.paren.close, expression.group, source.abc
( punctuation.paren.open, expression.group, source.abc
a keyword.letter, expression.group, source.abc
請注意,未被任何規則匹配的文字(如字串 xyz)會被包含在當前作用域中。檔案末尾的最後一個右括號是 expression.group 的一部分,即使 end 規則未被匹配,因為在 end 規則被匹配之前找到了 end-of-document。
嵌入語言
如果你的語法包含父語言中的嵌入語言,例如 HTML 中的 CSS 樣式塊,你可以使用 embeddedLanguages 貢獻點來告訴 VS Code 將嵌入語言視為獨立於父語言。這確保了括號匹配、註釋和其他基本語言功能在嵌入語言中按預期工作。
embeddedLanguages 貢獻點將嵌入語言中的作用域對映到一個頂層語言作用域。在下面的示例中,meta.embedded.block.javascript 作用域中的任何標記都將被視為 JavaScript 內容。
{
"contributes": {
"grammars": [
{
"path": "./syntaxes/abc.tmLanguage.json",
"scopeName": "source.abc",
"embeddedLanguages": {
"meta.embedded.block.javascript": "javascript"
}
}
]
}
}
現在,如果你嘗試在標記為 meta.embedded.block.javascript 的標記集合中註釋程式碼或觸發程式碼片段,它們將獲得正確的 // JavaScript 風格註釋和正確的 JavaScript 程式碼片段。
開發新的語法擴充套件
要快速建立新的語法擴充套件,請使用 VS Code 的 Yeoman 模板 執行 yo code 並選擇 New Language 選項。
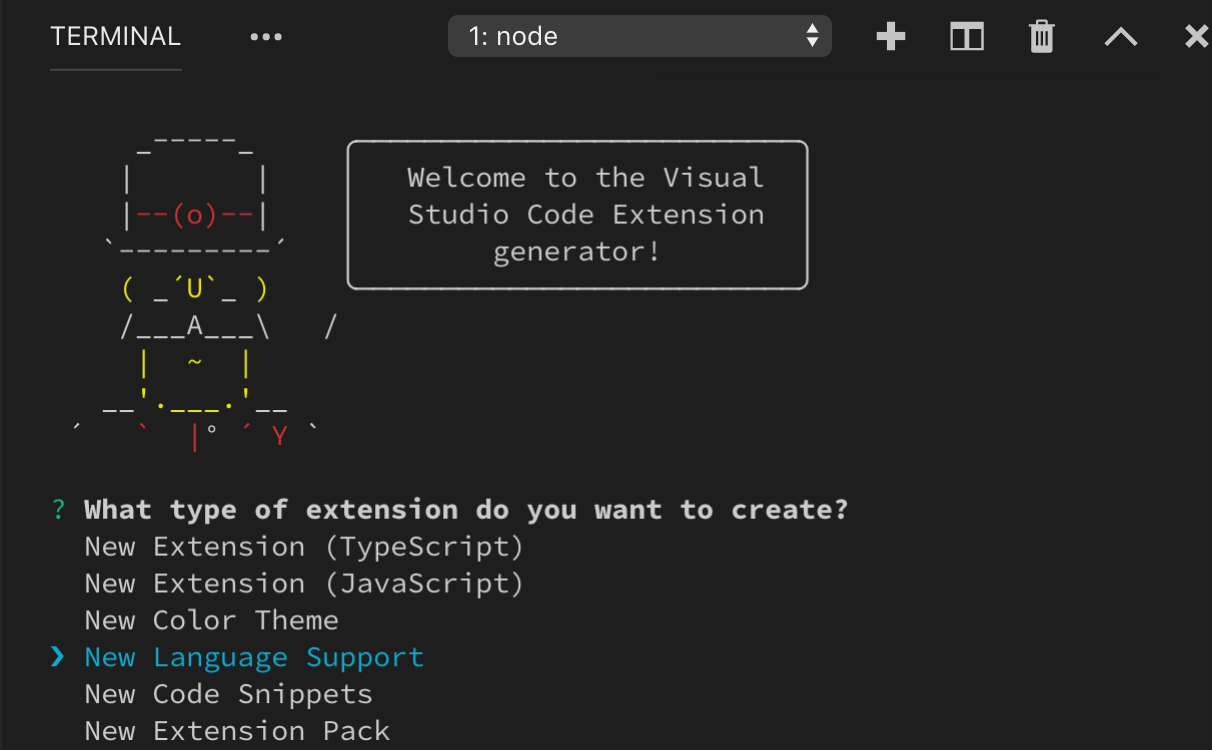
Yeoman 將引導你完成一些基本問題來構建新擴充套件。建立新語法時需要回答的重要問題是:
Language id- 你的語言的唯一識別符號。Language name- 你的語言的可讀名稱。Scope names- 你語法的根 TextMate 作用域名稱。
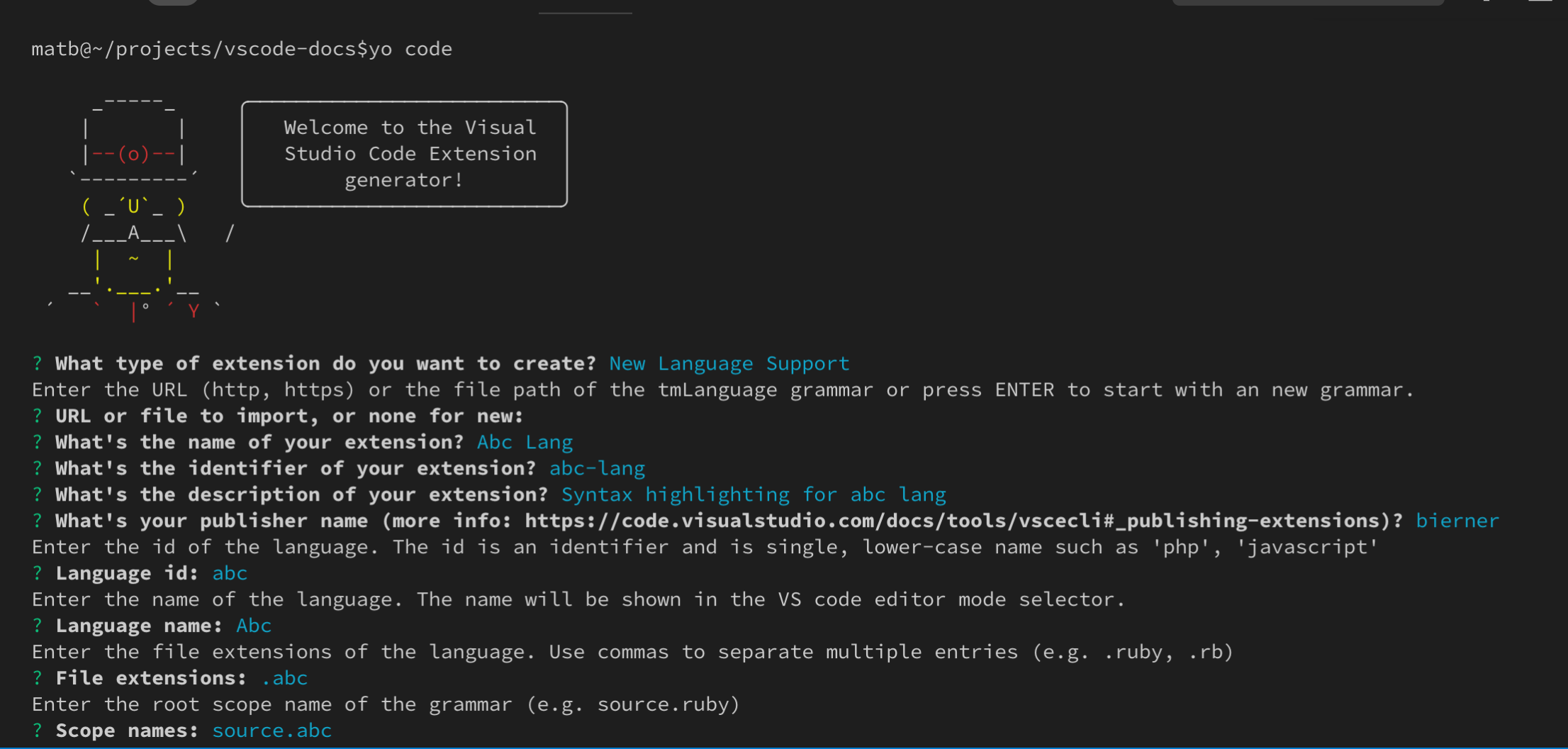
生成器假設你想為新語言定義一種新語法。如果你正在為現有語言建立語法,只需用目標語言的資訊填寫這些內容,並確保刪除生成的 package.json 中的 languages 貢獻點。
回答完所有問題後,Yeoman 將建立一個具有以下結構的新擴充套件:
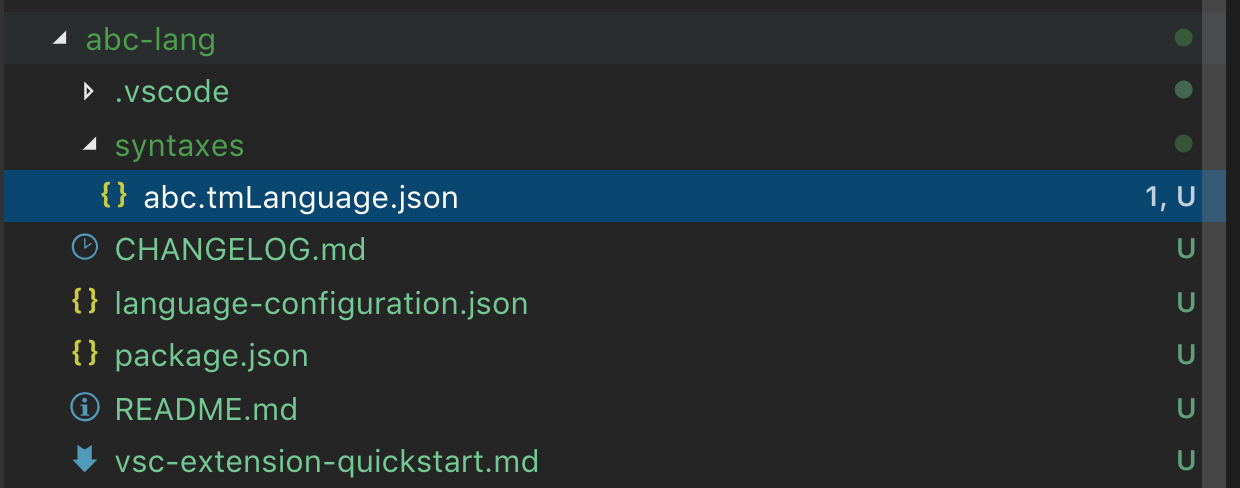
請記住,如果你為 VS Code 已知的語言貢獻語法,請務必刪除生成的 package.json 中的 languages 貢獻點。
轉換現有 TextMate 語法
yo code 也可以幫助將現有的 TextMate 語法轉換為 VS Code 擴充套件。同樣,首先執行 yo code 並選擇 Language extension。當被問及現有的語法檔案時,提供 .tmLanguage 或 .json TextMate 語法檔案的完整路徑。
使用 YAML 編寫語法
隨著語法變得越來越複雜,以 JSON 格式理解和維護它可能會變得困難。如果你發現自己編寫複雜的正則表示式或需要添加註釋來解釋語法的各個方面,請考慮改用 YAML 來定義你的語法。
YAML 語法與基於 JSON 的語法結構完全相同,但允許你使用 YAML 更簡潔的語法,以及多行字串和註釋等功能。
VS Code 只能載入 JSON 語法,因此基於 YAML 的語法必須轉換為 JSON。 js-yaml 包 和命令列工具可以輕鬆完成此操作。
# Install js-yaml as a development only dependency in your extension
$ npm install js-yaml --save-dev
# Use the command-line tool to convert the yaml grammar to json
$ npx js-yaml syntaxes/abc.tmLanguage.yaml > syntaxes/abc.tmLanguage.json
注入語法
注入語法允許你擴充套件現有語法。注入語法是一種常規的 TextMate 語法,它被注入到現有語法中的特定作用域。注入語法的應用示例:
- 高亮註釋中的
TODO等關鍵字。 - 為現有語法新增更具體的作用域資訊。
- 為 Markdown 圍欄程式碼塊新增新語言的高亮。
建立基本注入語法
注入語法透過 package.json 貢獻,就像常規語法一樣。但是,注入語法不指定 language,而是使用 injectTo 來指定要注入語法的目標語言作用域列表。
在本例中,我們將建立一個簡單的注入語法,用於高亮 JavaScript 註釋中的 TODO 關鍵字。要在 JavaScript 檔案中應用我們的注入語法,我們在 injectTo 中使用 source.js 目標語言作用域。
{
"contributes": {
"grammars": [
{
"path": "./syntaxes/injection.json",
"scopeName": "todo-comment.injection",
"injectTo": ["source.js"]
}
]
}
}
語法本身是標準的 TextMate 語法,但具有頂層的 injectionSelector 條目。injectionSelector 是一個作用域選擇器,用於指定應將注入語法應用於哪些作用域。在我們的示例中,我們希望高亮所有 // 註釋中的 TODO。使用 作用域檢查器,我們發現 JavaScript 的雙斜槓註釋的作用域是 comment.line.double-slash,所以我們的注入選擇器是 L:comment.line.double-slash。
{
"scopeName": "todo-comment.injection",
"injectionSelector": "L:comment.line.double-slash",
"patterns": [
{
"include": "#todo-keyword"
}
],
"repository": {
"todo-keyword": {
"match": "TODO",
"name": "keyword.todo"
}
}
}
注入選擇器中的 L: 表示注入新增到現有語法規則的左側。這基本上意味著我們的注入語法的規則將在任何現有語法規則之前應用。
嵌入語言
注入語法也可以為其父語法貢獻嵌入語言。與普通語法一樣,注入語法可以使用 embeddedLanguages 將嵌入語言的作用域對映到一個頂層語言作用域。
例如,一個突出顯示 JavaScript 字串中 SQL 查詢的擴充套件可以使用 embeddedLanguages 來確保標記為 meta.embedded.inline.sql 的字串中的所有標記都被視為 SQL,以實現括號匹配和程式碼片段選擇等基本語言功能。
{
"contributes": {
"grammars": [
{
"path": "./syntaxes/injection.json",
"scopeName": "sql-string.injection",
"injectTo": ["source.js"],
"embeddedLanguages": {
"meta.embedded.inline.sql": "sql"
}
}
]
}
}
標記型別和嵌入語言
注入語言和嵌入語言有一個額外的複雜性:預設情況下,VS Code 將字串內的所有標記視為字串內容,並將註釋中的所有標記視為標記內容。由於括號匹配和自動閉合對等功能在字串和註釋內部被停用,如果嵌入語言出現在字串或註釋內部,這些功能在嵌入語言中也將被停用。
要覆蓋此行為,你可以使用 meta.embedded.* 作用域來重置 VS Code 對標記為字串或註釋內容的標記。最好始終將嵌入語言包裝在 meta.embedded.* 作用域中,以確保 VS Code 正確處理嵌入語言。
如果你無法在語法中新增 meta.embedded.* 作用域,你也可以在語法的貢獻點中使用 tokenTypes 將特定作用域對映到內容模式。下面的 tokenTypes 部分確保 my.sql.template.string 作用域中的任何內容都被視為原始碼。
{
"contributes": {
"grammars": [
{
"path": "./syntaxes/injection.json",
"scopeName": "sql-string.injection",
"injectTo": ["source.js"],
"embeddedLanguages": {
"my.sql.template.string": "sql"
},
"tokenTypes": {
"my.sql.template.string": "other"
}
}
]
}
}
主題
主題化是關於為標記分配顏色和樣式。主題化規則在顏色主題中指定,但使用者可以在使用者設定中自定義主題化規則。
TextMate 主題規則在 tokenColors 中定義,其語法與常規 TextMate 主題相同。每條規則定義一個 TextMate 作用域選擇器以及結果的顏色和樣式。
在評估標記的顏色和樣式時,當前標記的作用域會與規則的選擇器進行匹配,以找到每個樣式屬性(前景、粗體、斜體、下劃線)的最具體規則。
顏色主題指南 描述瞭如何建立顏色主題。語義標記的主題化將在 語義高亮指南 中進行解釋。
作用域檢查器
VS Code 內建的作用域檢查器工具有助於除錯語法和語義標記。它顯示檔案當前位置的標記和語義標記的作用域,以及有關哪些主題規則應用於該標記的元資料。
可以透過命令面板中的 Developer: Inspect Editor Tokens and Scopes 命令觸發作用域檢查器,或為其 建立快捷鍵。
{
"key": "cmd+alt+shift+i",
"command": "editor.action.inspectTMScopes"
}
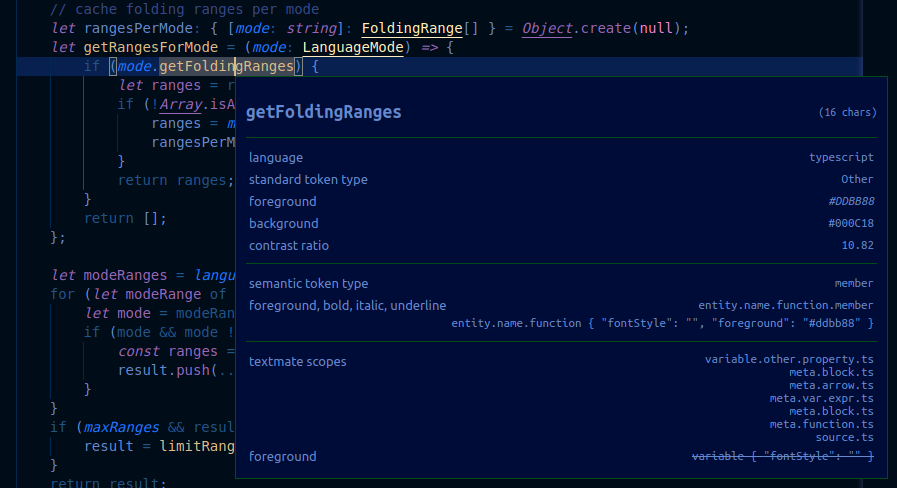
作用域檢查器顯示以下資訊:
- 當前標記。
- 關於標記的元資料以及其計算外觀的資訊。如果你正在處理嵌入語言,這裡重要的條目是
language和token type。 - 噹噹前語言存在語義標記提供程式並且當前主題支援語義高亮時,將顯示語義標記部分。它顯示當前的語義標記型別和修飾符,以及匹配語義標記型別和修飾符的主題規則。
- TextMate 部分顯示當前 TextMate 標記的作用域列表,最具體的作用域在頂部。它還顯示匹配作用域的最具體主題規則。這僅顯示負責標記當前樣式的規則,而不顯示覆蓋的規則。如果存在語義標記,則僅在與語義標記匹配的規則不同的情況下顯示主題規則。