透過名稱重整縮小 VS Code
2023 年 7 月 20 日,作者:Matt Bierner,@mattbierner
我們最近將 Visual Studio Code 釋出版 JavaScript 的大小減少了 20%。這相當於節省了超過 3.9 MB 的空間。當然,這比我們釋出說明中的一些單獨 gif 動圖要少,但這仍然不容小覷!這種減少不僅意味著需要下載和儲存在磁碟上的程式碼更少,它還提高了啟動時間,因為在執行 JavaScript 之前需要掃描的原始碼更少。考慮到我們是在沒有刪除任何程式碼且沒有對程式碼庫進行任何重大重構的情況下實現這一減少的,這已經相當不錯了。相反,我們所做的只是增加了一個新的構建步驟:名稱混淆(name mangling)。
在這篇文章中,我想分享我們是如何識別這個最佳化機會,探索解決問題的方法,並最終實現了這 20% 的大小減少。我想把這更多地看作是我們 VS Code 團隊如何處理工程問題的案例研究,而不是專注於混淆的具體細節。名稱混淆是一個巧妙的技巧,但在許多程式碼庫中可能不值得,而且我們具體的混淆方法很可能可以改進(或者根本不需要,具體取決於你的專案是如何構建的)。
識別問題
VS Code 團隊對效能充滿熱情,無論是最佳化熱程式碼路徑、減少 UI 重佈局還是加快啟動時間。這種熱情包括保持 VS Code JavaScript 大小的小巧。隨著 VS Code 除了桌面應用程式之外還在 web 上釋出(https://vscode.dev),程式碼大小變得更加受關注。積極監控程式碼大小使 VS Code 團隊成員能夠及時瞭解其變化。
不幸的是,這些變化幾乎總是增加。儘管我們對在 VS Code 中構建什麼功能進行了大量思考,但多年來新增新功能必然增加了我們釋出的程式碼量。例如,VS Code 的一個核心 JavaScript 檔案(workbench.js)現在的體積大約是八年前的四倍。現在,當你考慮到八年前 VS Code 缺少許多人今天認為必不可少的功能——例如編輯器標籤或內建終端——這種增加可能不像聽起來那麼糟糕,但也不是無足輕重。
這種 4 倍的體積增加也是在進行了大量持續的效能工程工作之後。同樣,這項工作主要是因為我們跟蹤程式碼大小並且非常討厭看到它增加。我們已經完成了許多簡單的程式碼大小最佳化,包括透過 esbuild 執行程式碼進行精簡。多年來,尋找進一步的節省變得越來越具有挑戰性。許多潛在的節省也不值得它們引入的風險,或者實現和維護它們所需的額外工程工作。這意味著我們不得不眼睜睜地看著 JavaScript 的大小慢慢增加。
然而,去年在 vscode.dev 上除錯我們精簡後的原始碼時,我注意到了一個令人驚訝的事情:我們精簡後的 JavaScript 仍然包含大量長的識別符號名稱,例如 extensionIgnoredRecommendationsService。這讓我很驚訝。我以為 esbuild 已經縮短了這些識別符號。事實證明,esbuild 確實在某些情況下透過一個名為“混淆”(mangling)(JavaScript 工具可能借鑑了一個與編譯語言的粗略相似的過程)的過程來縮短識別符號。
在精簡過程中,混淆會縮短長的識別符號名稱,將如下程式碼
const someLongVariableName = 123;
console.log(someLongVariableName);
轉換為更短的
const x = 123;
console.log(x);
由於 JavaScript 是以原始碼文字形式釋出的,減少識別符號名稱的長度實際上會減小程式的大小。我知道如果你來自編譯語言,這種最佳化可能看起來有點傻,但在美妙的 JavaScript 世界中,我們樂於接受能找到的任何此類勝利!
現在,在你急於將所有變數重新命名為單個字母之前,我想強調一下,像這樣的最佳化需要謹慎對待。如果潛在的最佳化使你的原始碼可讀性或可維護性降低,或者需要大量的體力勞動,那麼除非它能帶來真正驚人的改進,否則幾乎不值得。節省一些位元組是好事,但 hardly qualifies as spectacular。
如果我們能免費獲得像這樣的最佳化,例如讓我們的構建工具自動為我們完成,那麼這種計算就會改變。事實上,像 esbuild 這樣的智慧工具已經實現了識別符號混淆。這意味著我們可以繼續編寫我們的 veryLongAndDescriptiveNamesThatWouldMakeEvenObjectiveCProgrammersBlush,然後讓我們的構建工具為我們縮短它們!
儘管 esbuild 實現了混淆,但預設情況下,它只在確信混淆不會改變程式碼行為時才對名稱進行混淆。畢竟,讓打包工具破壞你的程式碼確實很糟糕。在實踐中,這意味著 esbuild 會混淆區域性變數名稱和引數名稱。這是安全的,除非你的程式碼正在做一些真正荒謬的事情(在這種情況下,你可能需要擔心比程式碼大小更大的問題)。
然而,esbuild 的保守方法意味著它會跳過混淆許多名稱,因為它無法確定更改它們是否安全。作為一個簡單的例子,說明事情可能出錯,請考慮
const obj = { longPropertyName: 123 };
function lookup(prop) {
return obj[prop];
}
console.log(lookup('longPropertyName'));
如果混淆將 longPropertyName 更改為 x,則下一行的動態查詢將不再起作用
const obj = { x: 123 }; // Here `longPropertyName` gets rewritten to `x`
function lookup(prop) {
return obj[prop];
}
console.log(lookup('longPropertyName')); // But this reference doesn't and now the lookup is broken
請注意上面的程式碼中,我們仍然嘗試使用 longPropertyName 來訪問屬性,即使屬性本身已在混淆期間更改。
雖然這個例子是人為設計的,但在真實程式碼中,這些破壞實際上有多種發生方式
- 動態屬性訪問。
- 將物件序列化或解析 JSON 以符合預期的物件形狀。
- 你公開的 API(消費者將不知道新的混淆名稱。)
- 你使用的 API(包括 DOM API。)
儘管你可以強制 esbuild 混淆它找到的幾乎所有名稱,但由於上述原因,這樣做會完全破壞 VS Code。
儘管如此,我仍然無法擺脫一種感覺,即我們必須能夠在 VS Code 程式碼庫中做得更好。如果不能混淆每個名稱,也許我們至少可以找到一些我們可以安全混淆的名稱子集。
使用私有屬性的錯誤開始
回顧我們精簡後的原始碼,另一件讓我眼前一亮的事情是我看到了多少以 _ 開頭的長名稱。按照慣例,這表示私有屬性。私有屬性當然可以安全地混淆,而類外的程式碼對此一無所知,對吧?等等,esbuild 不應該已經為我們做這件事了嗎?然而我知道編寫 esbuild 的人絕非等閒之輩。如果 esbuild 沒有混淆私有屬性,那幾乎肯定是有充分理由的。
隨著我對這個問題的思考越來越多,我意識到私有屬性受到與上面 longPropertyName 示例中所示的相同動態屬性查詢問題的影響。我確信像你這樣聰明的 TypeScript 程式設計師絕不會編寫這樣的程式碼,但動態模式在現實世界的程式碼庫中很常見,以至於 esbuild 選擇謹慎行事。
還要記住,TypeScript 中的 private 關鍵字實際上只是一個禮貌的建議。當 TypeScript 程式碼編譯為 JavaScript 時,private 關鍵字基本上被刪除。這意味著沒有什麼能阻止類外的粗魯程式碼伸進來隨意訪問私有屬性
class Foo {
private bar = 123;
}
const foo: any = new Foo();
console.log(foo.bar);
希望你的程式碼沒有直接做這種可疑的事情,但粗心地更改屬性名稱可能會以許多有趣且意想不到的方式讓你吃虧,例如物件展開、序列化以及不同類共享公共屬性名稱時。
值得慶幸的是,我意識到在 VS Code 中我有一個巨大的優勢:我正在處理一個(大部分)健全的程式碼庫。我可以做出許多 esbuild 不能做出的假設,例如沒有動態私有屬性訪問或錯誤的 any 訪問。這進一步簡化了我面臨的問題。
因此,我和 Johannes Rieken (@johannesrieken) 開始探索私有屬性混淆。我們的第一個想法是嘗試在我們的程式碼庫中普遍採用 JavaScript 的原生 #private 欄位。私有欄位不僅不受上述所有問題的影響,而且它們已經被 esbuild 自動混淆。更接近純粹的 JavaScript 也很有吸引力。
然而,我們很快就放棄了這種方法,因為它需要大量的(意味著有風險的)程式碼更改,包括刪除所有對引數屬性的使用。作為一項相對較新的功能,私有欄位也尚未在所有執行時中進行最佳化。使用它們可能會引入從可以忽略不計到大約 95% 的減速!雖然從長遠來看這可能是正確的改變,但這不是我們現在需要的。
接下來我們發現 esbuild 可以選擇性地混淆與給定正則表示式匹配的屬性。然而,這個正則表示式只匹配識別符號名稱。雖然這意味著我們無法知道該屬性是否在 TypeScript 中宣告為 private,但我們可以嘗試混淆所有以 _ 開頭的屬性,我們希望這隻會包括私有和受保護的屬性。
很快,我們就構建了一個所有 _ 屬性都經過混淆的構建版本。不錯!這證明了私有屬性混淆是可行的,並帶來了一些不錯的節省,儘管遠低於我們的預期。
不幸的是,僅僅基於名稱進行混淆有一些嚴重的缺點,包括要求我們程式碼庫中所有私有屬性都以 _ 開頭。VS Code 程式碼庫並不始終遵循此命名約定,而且我們還有一些以 _ 開頭的公共屬性(通常在屬性需要外部訪問但不應被視為 API 時使用,例如在測試中)。
我們也不完全相信混淆後的程式碼是正確的。當然,我們可以執行測試或嘗試啟動 VS Code,但這很耗時,而且如果我們忽略了不太常見的程式碼路徑怎麼辦?我們無法 100% 確定我們只混淆了私有屬性而沒有觸及其他程式碼。這種方法看起來既有風險又難以採用。
使用 TypeScript confidentyly 混淆
思考如何對混淆構建步驟更有信心時,我們想到了一個新主意:如果 TypeScript 可以為我們驗證混淆後的程式碼呢?正如 TypeScript 可以在普通程式碼中捕獲未知屬性訪問一樣,TypeScript 編譯器應該能夠捕獲屬性已被混淆但對它的引用未正確更新的情況。我們不必混淆編譯後的 JavaScript,而是可以混淆我們的 TypeScript 原始碼,然後用混淆後的識別符號名稱編譯新的 TypeScript。對混淆後的原始碼進行編譯步驟將使我們更有信心沒有意外破壞程式碼。
不僅如此,透過使用 TypeScript,我們可以真正找到所有 private 屬性(而不是那些恰好以 _ 開頭的屬性)。我們甚至可以使用 TypeScript 現有的 rename 功能來智慧地重新命名符號,而不會以意想不到的方式改變物件形狀。
渴望嘗試這種新方法,我們很快就提出了新的混淆構建步驟,它大致如下工作
for each private or protected property in codebase (found using TypeScript's AST):
if the property should be mangled:
Compute a new name by looking for an unused symbol name
Use TypeScript to generate a rename edit for all references to the property
Apply all rename edits to our typescript source
Compile the new edited TypeScript sources with the mangled names
對於這種看似天真的方法,它出乎意料地奏效了!嗯,至少大部分是這樣。
雖然我們對 TypeScript 能夠在我們整個程式碼庫中生成數千次正確編輯印象深刻,但我們還必須新增邏輯來處理一些邊緣情況
-
一個新的私有屬性名稱在當前類中是唯一的還不夠,它還必須在當前類的所有超類和子類中都是唯一的。根本原因再次是 TypeScript 的
private關鍵字只是一個編譯時修飾符,它實際上並不強制超類和子類不能訪問私有屬性。如果不小心,重新命名可能會引入名稱衝突(值得慶幸的是,TypeScript 會將這些報告為錯誤)。 -
在我們的程式碼中的某些地方,子類將繼承的受保護屬性公開。雖然其中許多是錯誤,但我們還添加了程式碼來停用這些情況下的混淆。
在為這些情況新增程式碼後,我們很快就有了可用的構建版本。透過混淆私有屬性,VS Code 的主 workbench.js 指令碼大小從 12.3 MB 變為 10.6 MB,減少了近 14%。這也帶來了 5% 的程式碼載入速度提升,因為需要掃描的原始碼更少。考慮到除了對原始碼中不安全模式進行一些非常小的修復之外,這些節省基本上是免費的,這還不錯。
經驗教訓和進一步的工作
混淆私有屬性表明,在 VS Code 中仍然可以找到顯著的改進,而無需訴諸於大規模的程式碼更改或昂貴的重寫。在這種情況下,我懷疑多年來其他人曾檢視過 VS Code 精簡後的原始碼,並對那些長名稱感到疑惑。然而,解決這個問題可能看起來無法安全地完成,或者可能看起來不值得進行潛在的大量工程投資。
這次我們成功的關鍵是確定了一個案例(私有屬性),其中名稱混淆很可能是安全的,並且最佳化仍然會帶來顯著的改進。然後我們考慮瞭如何儘可能安全地進行這種更改。這意味著首先使用 TypeScript 的工具來自信地重新命名識別符號,然後再次使用 TypeScript 來確保我們新混淆的原始碼仍然可以正確編譯。在此過程中,我們的程式碼已經遵循了大多數 TypeScript 最佳實踐,並且有測試覆蓋了許多常見的 VS Code 程式碼路徑,這極大地幫助了我們。所有這些結合在一起,使得 Joh 和我可以在業餘時間工作,在對其他從事 VS Code 開發的人員幾乎沒有影響的情況下發布了相當徹底的更改。
然而,混淆的故事還沒有結束。檢視我們新混淆和精簡後的原始碼,我沮喪地看到了 provideWorkspaceTrustExtensionProposals 和許多其他冗長的名稱。最值得注意的是幾乎 5000 次出現的 localize(我們用於 UI 中顯示的字串的函式)。顯然還有改進的空間。
使用與混淆私有屬性相同的方法和技術,我很快確定了另一個常見的程式碼模式,我們可以安全地混淆,並具有很高的投資回報:匯出的符號名稱。只要這些匯出僅在內部使用,我就相信我們可以縮短它們而不會改變程式碼的行為。
這在很大程度上被證明是正確的,儘管又出現了一些併發症。例如,我們必須確保不會意外觸及擴充套件使用的 API,並且還必須免除一些從 TypeScript 匯出但隨後從非型別化 JavaScript 呼叫的符號(通常這些是工作執行緒或程序的入口點)。
匯出混淆工作在上次迭代中釋出,進一步將 workbench.js 的大小從 10.6 MB 減少到 9.8 MB。總的來說,這個檔案現在比沒有混淆時小 20%。在整個 VS Code 中,混淆從我們編譯的原始碼中刪除了 3.9 MB 的 JavaScript 程式碼。這不僅減少了下載大小和安裝大小,而且每次啟動 VS Code 時需要掃描的 JavaScript 也減少了 3.9 MB。
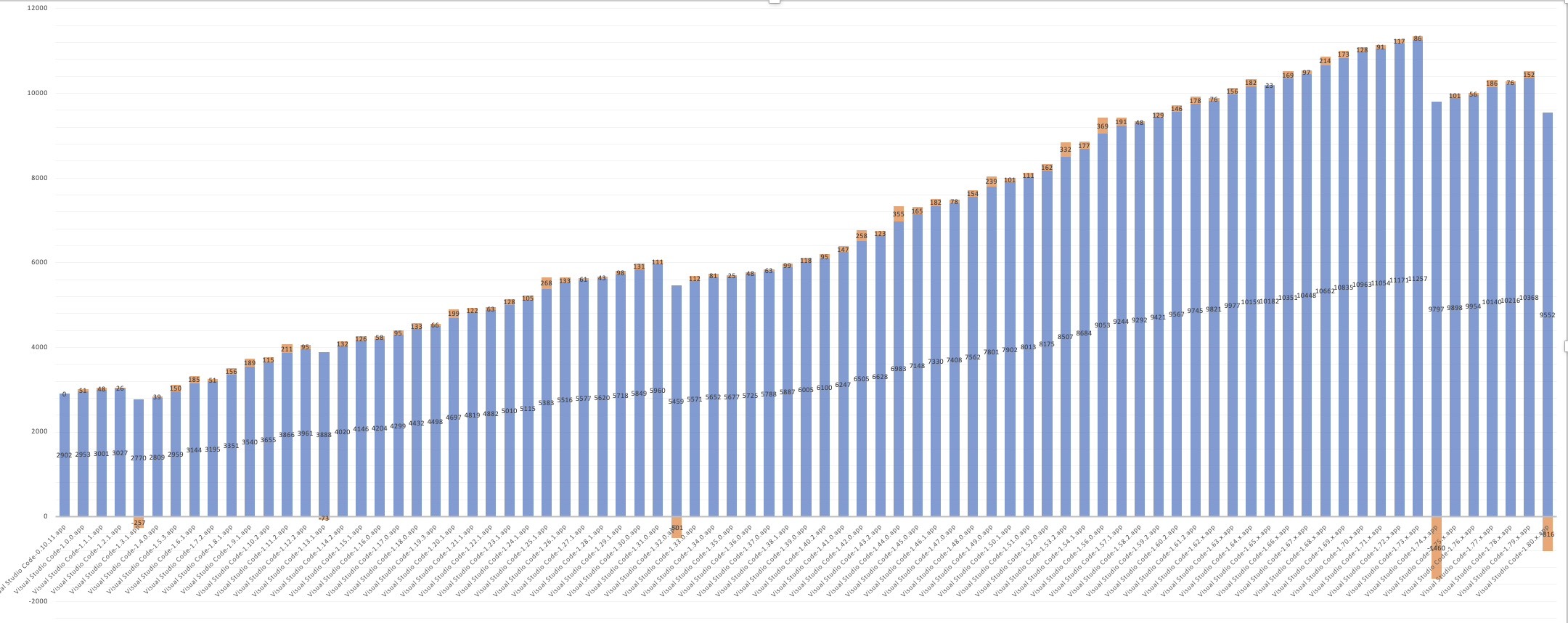
此圖表顯示了 workbench.js 隨時間的大小。請注意右側的兩個下降。VS Code 1.74 中的第一次大幅下降是混淆私有屬性的結果。1.80 中的第二次較小下降是混淆匯出的結果。

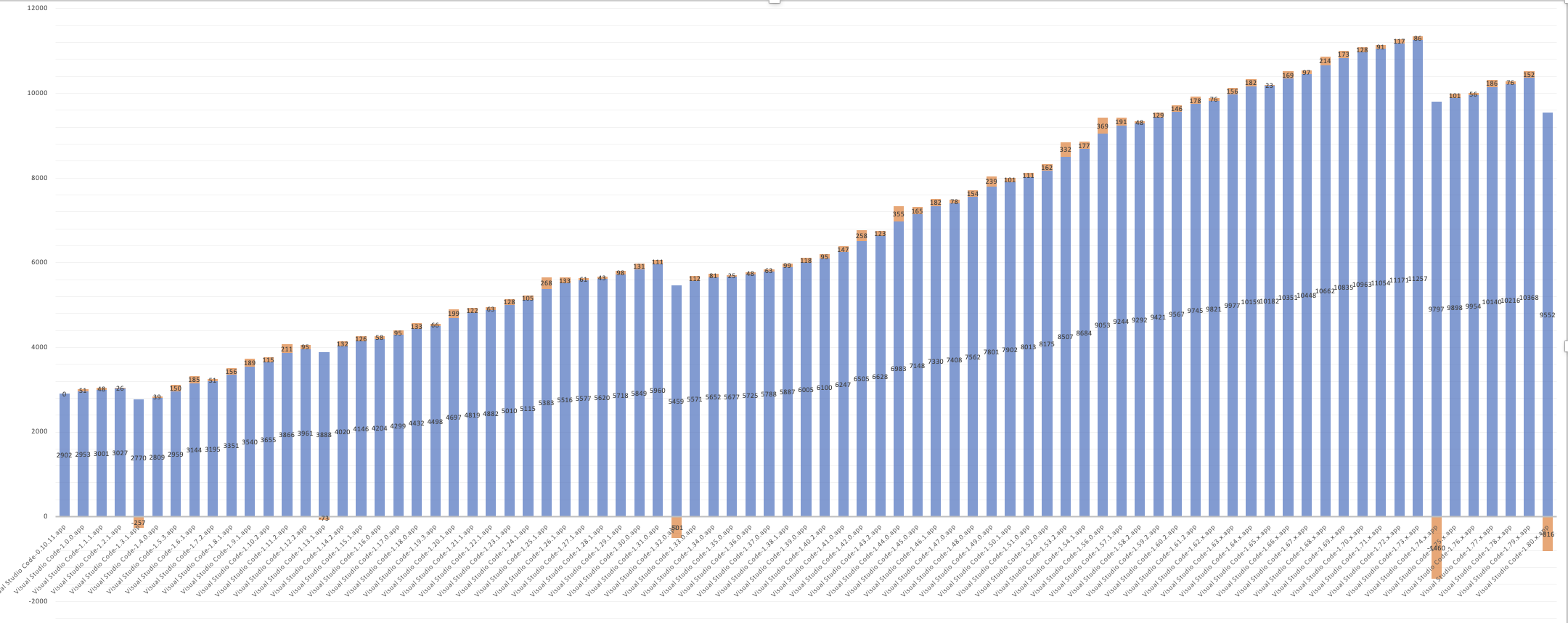
我們的混淆實現無疑可以改進,因為我們精簡後的原始碼仍然包含大量長名稱。如果這樣做值得,並且如果我們能想出一種安全的方法,我們可能會進一步研究這些。理想情況下,總有一天所有這些工作根本不需要。原生私有屬性已經被自動混淆,我們的構建工具將有望更好地最佳化我們整個程式碼庫中的程式碼。您可以檢視我們當前的混淆實現。
我們一直在努力使 VS Code 和我們的程式碼庫變得更好,我認為混淆工作是展示我們如何處理這個問題的絕佳示例。最佳化是一個持續的過程,而不是一次性的事情。透過持續監控我們的程式碼大小,我們意識到了它隨著時間的推移是如何增長的。這種意識無疑有助於防止我們的程式碼大小進一步膨脹,並鼓勵我們始終尋找改進。儘管混淆是一種看起來很有吸引力的技術,但最初考慮它風險太大。只有當我們努力降低這種風險,建立正確的安全網,並使採用混淆的成本幾乎為零時,我們才最終有信心在構建中啟用它。我為最終結果感到非常自豪,也為我們實現它的方式感到自豪。
程式設計愉快,
Matt Bierner,VS Code 團隊成員 @mattbierner
感謝 Johannes Rieken 在實現混淆方面所做的關鍵工作,感謝 TypeScript 團隊構建了使我們能夠安全實現混淆的工具,感謝 esbuild 提供了極快的打包工具,感謝整個 VS Code 團隊構建了適合這種最佳化的程式碼庫。最後但同樣重要的是,非常感謝 V8 團隊和所有其他 JS 引擎,感謝他們總是讓我們看起來很快,儘管我們向他們扔去了堆積如山的混淆 JavaScript。